Adam Gleave, Michael Dennis, Shane Legg, Stuart Russell and Jan Leike
Apr 20, 2021
Cross-posted from the DeepMind Safety blog.
In many reinforcement learning problems the objective is too complex to be specified procedurally, and a reward function must instead be learned from user data. However, how can you tell if a learned reward function actually captures user preferences? Our method, Equivalent-Policy Invariant Comparison (EPIC), allows one to evaluate a reward function by computing how similar it is to other reward functions. EPIC can be used to benchmark reward learning algorithms by comparing learned reward functions to a ground-truth reward.
It can also be used to validate learned reward functions prior to deployment, by comparing them against reward functions learned via different techniques or data sources.
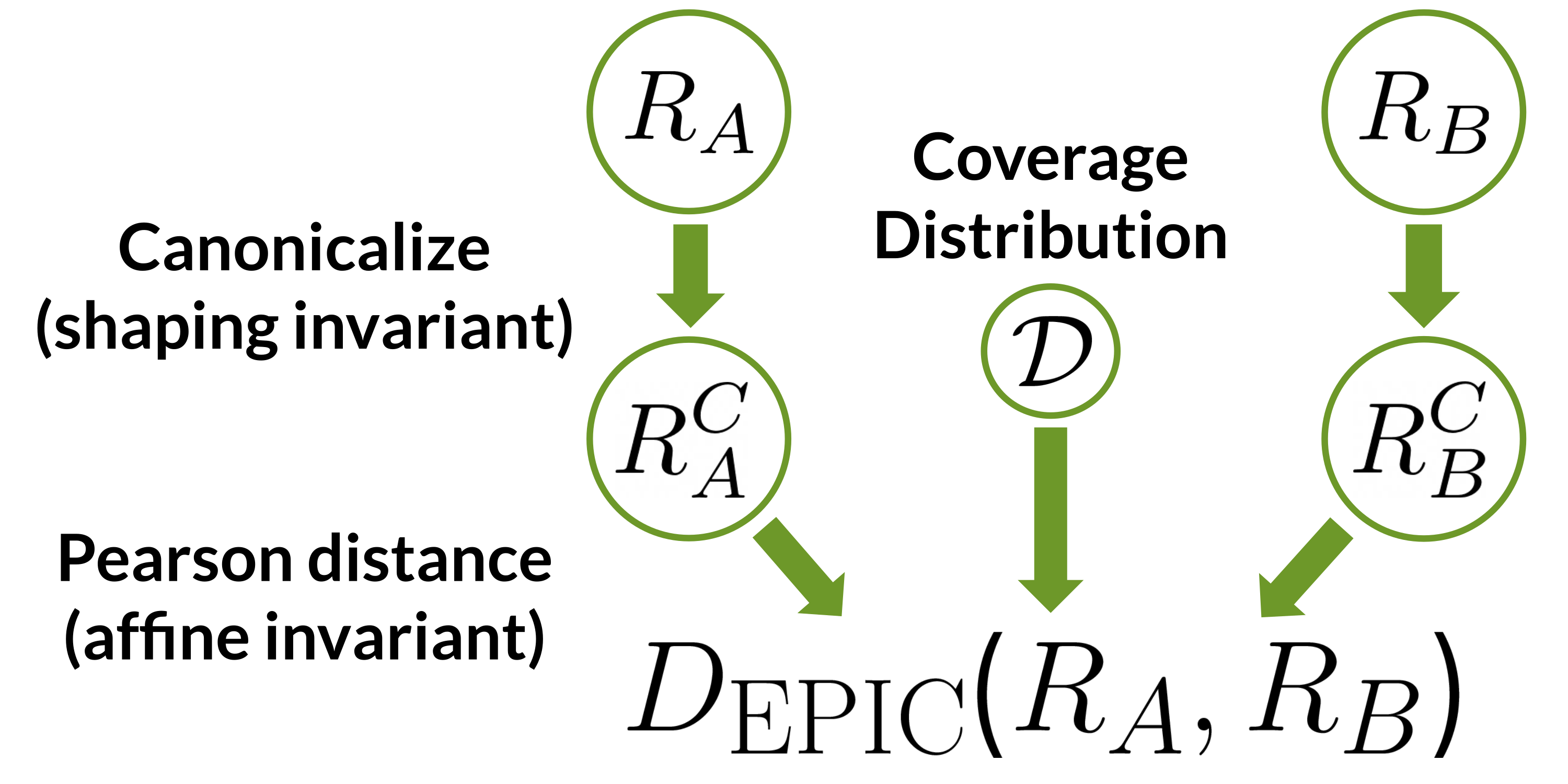
Figure 1: EPIC compares reward functions $R_a$ and $R_b$ by first mapping them to canonical representatives and then computing the Pearson distance between the canonical representatives on a coverage distribution $\mathcal{D}$. Canonicalization removes the effect of potential shaping, and Pearson distance is invariant to positive affine transformations.
Continue
Model-based reinforcement learning (MBRL) is a variant of the iterative
learning framework, reinforcement learning, that includes a structured
component of the system that is solely optimized to model the environment
dynamics. Learning a model is broadly motivated from biology, optimal control,
and more – it is grounded in natural human intuition of planning before acting. This intuitive
grounding, however, results in a more complicated learning process. In this
post, we discuss how model-based reinforcement learning is more susceptible to
parameter tuning and how AutoML can help in finding very well performing
parameter settings and schedules. Below, left is the expected behavior of an
agent maximizing velocity on a “Half Cheetah” robotic task, and to the right is
what our paper with hyperparameter tuning finds.


Continue
Transformers have been successfully applied to a wide variety of modalities:
natural language, vision, protein modeling, music, robotics, and more. A common
trend with using large models is to train a transformer on a large amount of
training data, and then finetune it on a downstream task. This enables the
models to utilize generalizable high-level embeddings trained on a large
dataset to avoid overfitting to a small task-relevant dataset.
We investigate a new setting where instead of transferring the high-level
embeddings, we instead transfer the intermediate computation modules – instead
of pretraining on a large image dataset and finetuning on a small image
dataset, we might instead pretrain on a large language dataset and finetune on
a small image dataset. Unlike conventional ideas that suggest the attention
mechanism is specific to the training modality, we find that the self-attention
layers can generalize to other modalities without finetuning.
Continue
Ben Eysenbach
Mar 9, 2021
Nearly all real-world applications of reinforcement learning involve some degree of shift between the training environment and the testing environment. However, prior work has observed that even small shifts in the environment cause most RL algorithms to perform markedly worse.
As we aim to scale reinforcement learning algorithms and apply them in the real world, it is increasingly important to learn policies that are robust to changes in the environment.
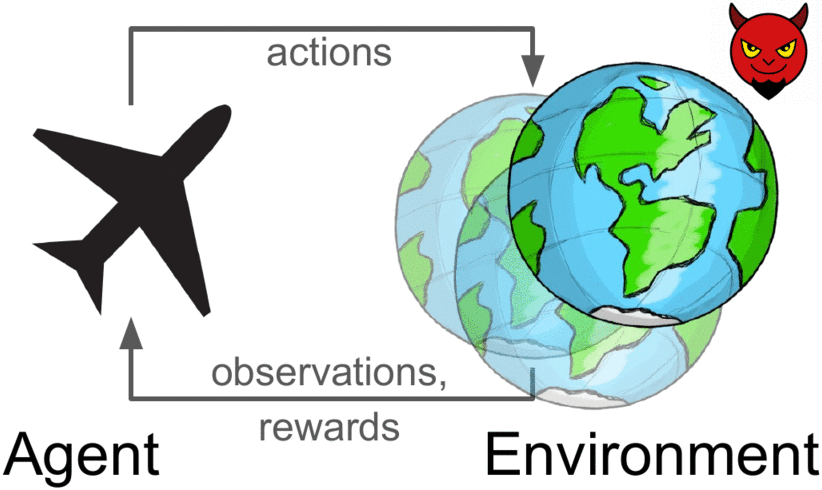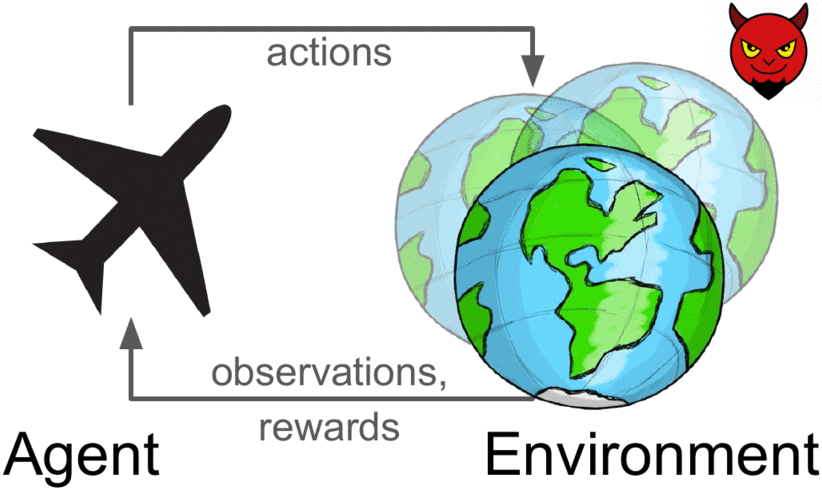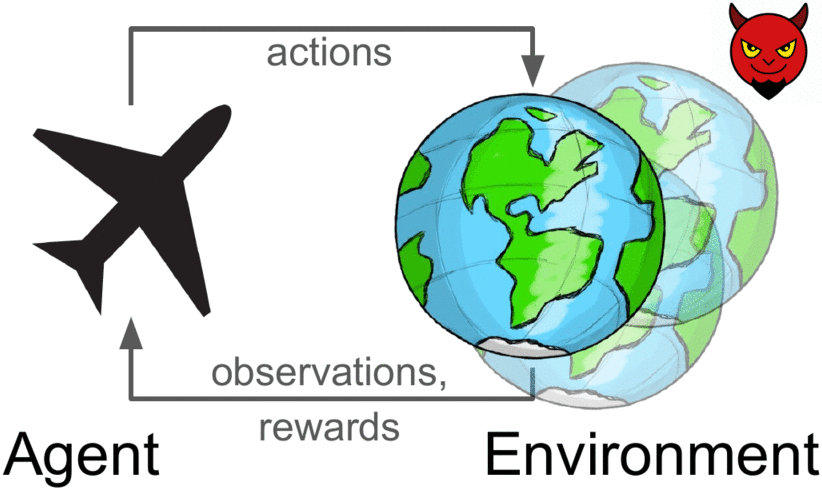
Robust reinforcement learning maximizes reward on an adversarially-chosen environment.
Broadly, prior approaches to handling distribution shift in RL aim to maximize performance in either the average case or the worst case. The first set of approaches, such as domain randomization, train a policy on a distribution of environments, and optimize the average performance of the policy on these environments. While these methods have been successfully applied to a number of areas
(e.g., self-driving cars, robot locomotion and manipulation),
their success rests critically on the design of the distribution of environments.
Moreover, policies that do well on average are not guaranteed to get high reward on every environment. The policy that gets the highest reward on average might get very low reward on a small fraction of environments. The second set of approaches, typically referred to as robust RL, focus on the worst-case scenarios. The aim is to find a policy that gets high reward on every environment within some set. Robust RL can equivalently be viewed as a two-player game between the policy and an environment adversary. The policy tries to get high reward, while the environment adversary tries to tweak the dynamics and reward function of the environment so that the policy gets lower reward. One important property of the robust approach is that, unlike domain randomization, it is invariant to the ratio of easy and hard tasks. Whereas robust RL always evaluates a policy on the most challenging tasks, domain randomization will predict that the policy is better if it is evaluated on a distribution of environments with more easy tasks.
Continue



Our method learns a task in a fixed, simulated environment and quickly adapts
to new environments (e.g. the real world) solely from online interaction during
deployment.
The ability for humans to generalize their knowledge and experiences to new
situations is remarkable, yet poorly understood. For example, imagine a human
driver that has only ever driven around their city in clear weather. Even
though they never encountered true diversity in driving conditions, they have
acquired the fundamental skill of driving, and can adapt reasonably fast to
driving in neighboring cities, in rainy or windy weather, or even driving a
different car, without much practice nor additional driver’s lessons. While
humans excel at adaptation, building intelligent systems with common-sense
knowledge and the ability to quickly adapt to new situations is a long-standing
problem in artificial intelligence.
Continue
The Successor Representation, Gamma-Models, and Infinite-Horizon Prediction
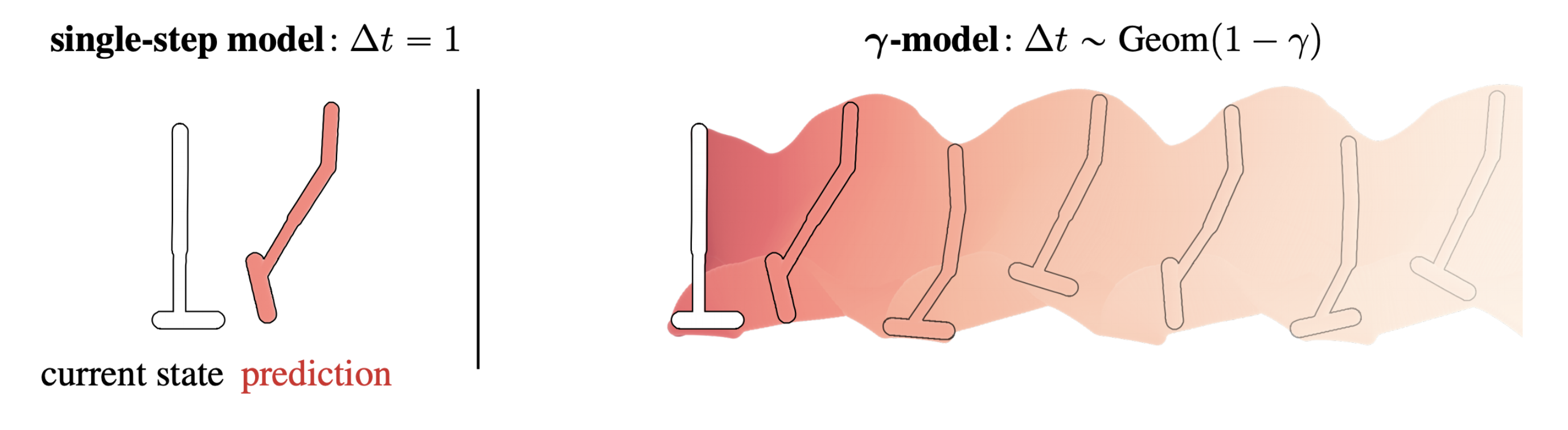
Standard single-step models have a horizon of one. This post describes a method for training predictive dynamics models in continuous state spaces with an infinite, probabilistic horizon.
Reinforcement learning algorithms are frequently categorized by whether they predict future states at any point in their decision-making process. Those that do are called model-based, and those that do not are dubbed model-free. This classification is so common that we mostly take it for granted these days; I am guilty of using it myself. However, this distinction is not as clear-cut as it may initially seem.
In this post, I will talk about an alternative view that emphases the mechanism of prediction instead of the content of prediction. This shift in focus brings into relief a space between model-based and model-free methods that contains exciting directions for reinforcement learning. The first half of this post describes some of the classic tools in this space, including
generalized value functions and the successor representation. The latter half is based on our recent paper about infinite-horizon predictive models, for which code is available here.
Continue
Most likely not.
Yet, OpenAI’s GPT-2 language model does know how to reach a certain Peter W--- (name redacted for privacy). When prompted with a short snippet of Internet text, the model accurately generates Peter’s contact information, including his work address, email, phone, and fax:
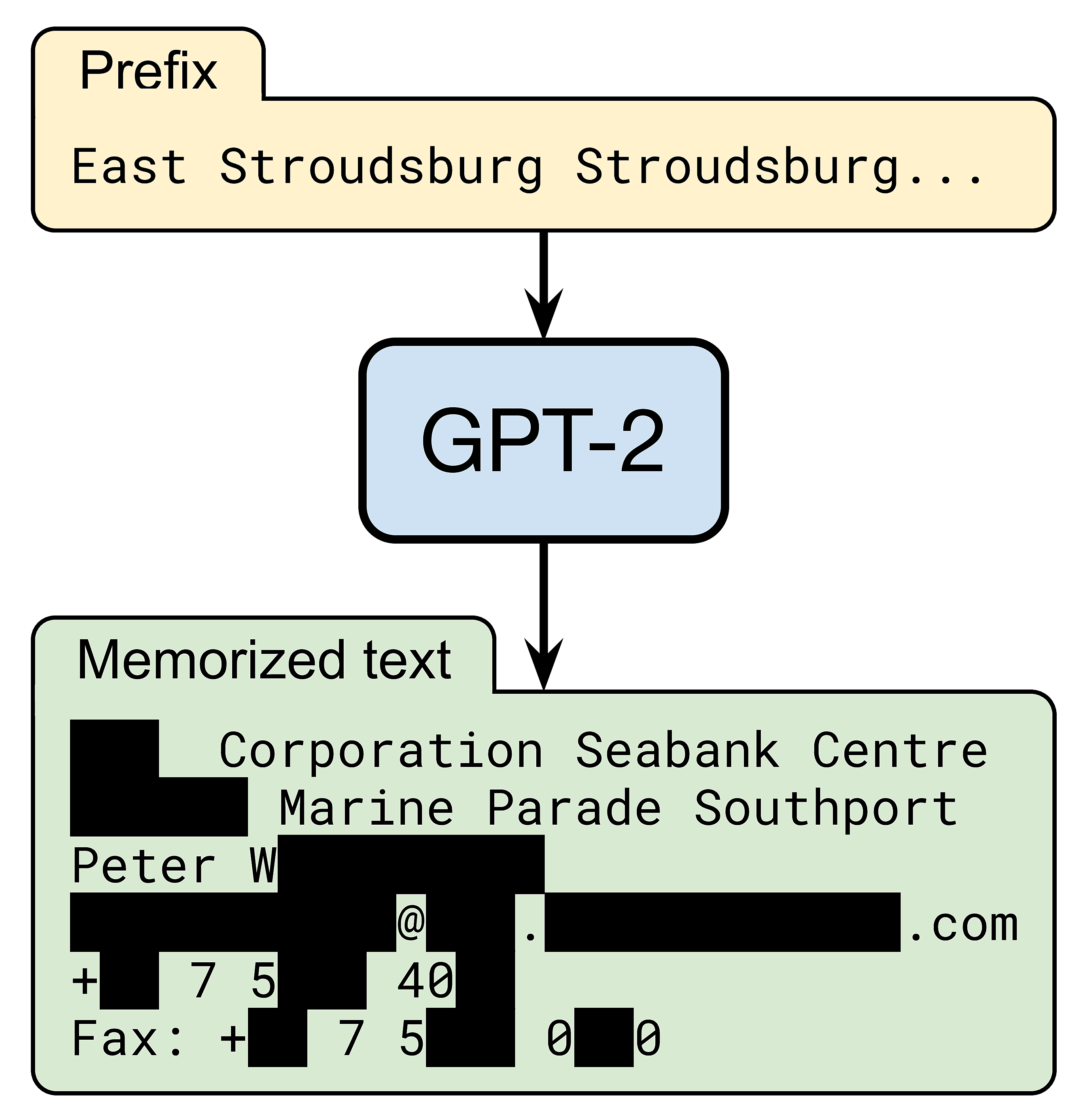
In our recent paper, we evaluate how large language models memorize and regurgitate such rare snippets of their training data. We focus on GPT-2 and find that at least 0.1% of its text generations (a very conservative estimate) contain long verbatim strings that are “copy-pasted” from a document in its training set.
Such memorization would be an obvious issue for language models that are trained on private data, e.g., on users’ emails, as the model might inadvertently output a user’s sensitive conversations. Yet, even for models that are trained on public data from the Web (e.g., GPT-2, GPT-3, T5, RoBERTa, TuringNLG), memorization of training data raises multiple challenging regulatory questions, ranging from misuse of personally identifiable information to copyright infringement.
Continue
Deep reinforcement learning has made significant progress in the last few years, with success stories in robotic control, game playing and science problems. While RL methods present a general paradigm where an agent learns from its own interaction with an environment, this requirement for “active” data collection is also a major hindrance in the application of RL methods to real-world problems, since active data collection is often expensive and potentially unsafe. An alternative “data-driven” paradigm of RL, referred to as offline RL (or batch RL) has recently regained popularity as a viable path towards effective real-world RL. As shown in the figure below, offline RL requires learning skills solely from previously collected datasets, without any active environment interaction. It provides a way to utilize previously collected datasets from a variety of sources, including human demonstrations, prior experiments, domain-specific solutions and even data from different but related problems, to build complex decision-making engines.

Continue
Many tasks that we do on a regular basis, such as navigating a city, cooking a
meal, or loading a dishwasher, require planning over extended periods of time.
Accomplishing these tasks may seem simple to us; however, reasoning over long
time horizons remains a major challenge for today’s Reinforcement Learning (RL)
algorithms. While unable to plan over long horizons, deep RL algorithms excel
at learning policies for short horizon tasks, such as robotic grasping,
directly from pixels. At the same time, classical planning methods such as
Dijkstra’s algorithm and A$^*$ search can plan over long time horizons, but
they require hand-specified or task-specific abstract representations of the
environment as input.
To achieve the best of both worlds, state-of-the-art visual navigation methods
have applied classical search methods to learned graphs. In particular, SPTM [2]
and SoRB [3] use a replay buffer of observations as nodes in a graph and learn
a parametric distance function to draw edges in the graph. These methods have
been successfully applied to long-horizon simulated navigation tasks that were
too challenging for previous methods to solve.
Continue