
Figure 1: CUDA-to-MLX optimization translation map. CUDA optimization knowledge can be translated into architecture-native MLX strategies rather than copied instruction-for-instruction.
We face a new epoch in computing. Hardware is changing rapidly — not just faster GPUs, but a growing range of chips from different vendors, each with its own architecture and often tailored to specific AI workloads. Software is changing just as fast, and AI coding tools now generate in minutes what took months of effort a few years ago.
Continue
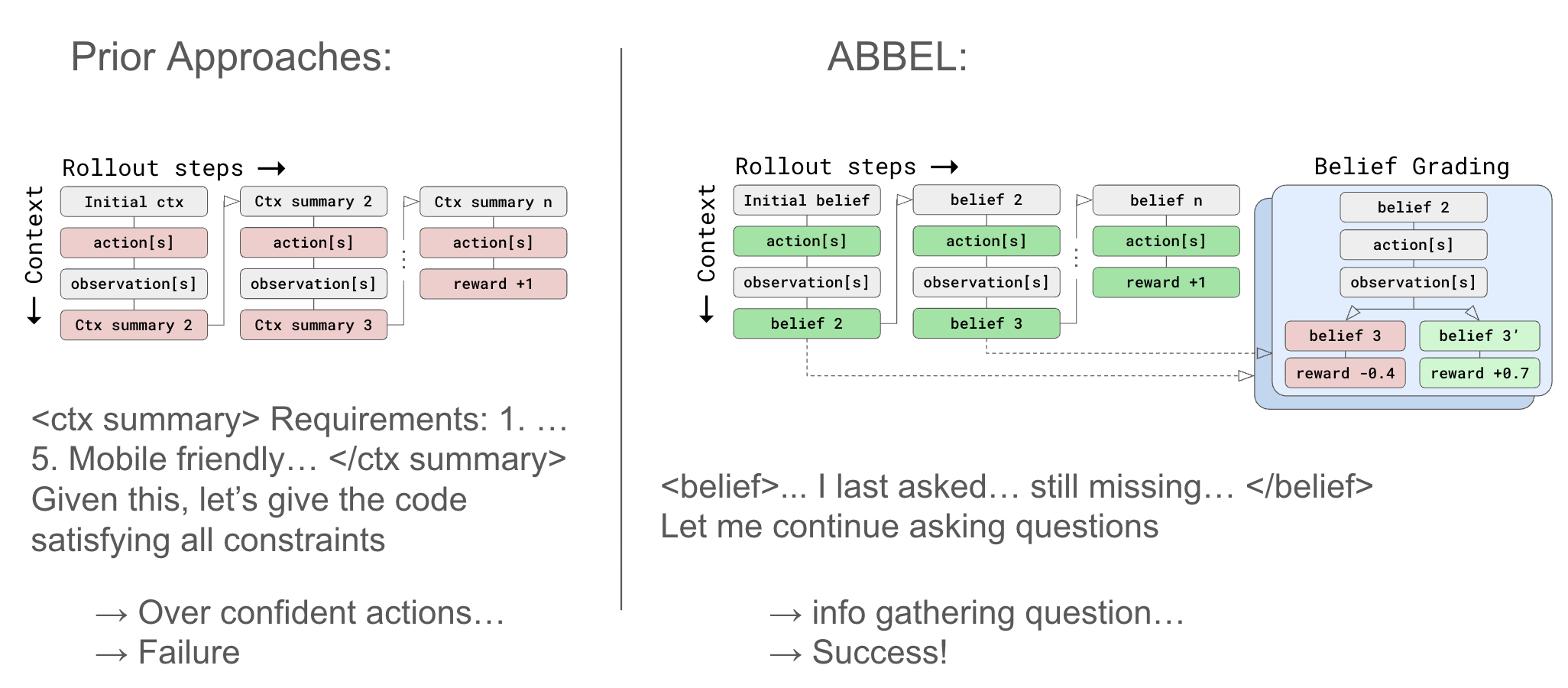 Overview of ABBEL compared to traditional recursive summarization. Beliefs replace the full interaction history as the agent’s working context, and belief grading improves performance by
supervising the contents of each belief state..
Overview of ABBEL compared to traditional recursive summarization. Beliefs replace the full interaction history as the agent’s working context, and belief grading improves performance by
supervising the contents of each belief state..
As task horizons grow, LLM contexts can’t scale forever. Self-summarization enables concise, interpretable contexts, but at a significant performance cost, especially for human assistance domains where high quality data is scarce, e.g., collaborative code generation. We address this with ABBEL: a framework that isolates and supervises the information content of summaries in the form of natural-language belief states.
Continue
... government of the people, by the people, for the people ...
— Abraham Lincoln, Gettysburg Address (1863)
The cost of AI is dropping rapidly. GPT-4-class capabilities cost roughly $30 per million tokens in early 2023; today the same runs under $1, and some providers are pushing costs below $0.10. Across benchmarks, inference prices have fallen between 9x and 900x per year, with a median decline near 50x. Even frontier models are getting dramatically cheaper each generation, with open-source models following closely behind. And crucially, even if “Nobel-Prize-winning genius-level” intelligence isn’t here yet, the intelligence that suffices for the vast majority of knowledge work is here today, and getting cheaper by the month. At this rate, we are soon entering the era of virtually free intelligence—the kind that is more than enough for everyday knowledge work.

Continue
Berkeley AI Research Editors
Jul 1, 2026
Congratulations to the Berkeley Artificial Intelligence Research (BAIR) Lab class of 2026! This year, BAIR celebrates another remarkable group of Ph.D. graduates whose curiosity, creativity, and perseverance have pushed the frontiers of artificial intelligence and machine learning.
Their work spans the breadth of modern AI — robotics and embodied intelligence, large language models and reasoning, computer vision, generative modeling, AI safety, human-AI interaction, AI for science and healthcare, and much more. Along the way, they have published influential research, built systems with real-world impact, mentored their peers, and shaped the BAIR community for the better.
Now they are headed everywhere ideas travel: to faculty and postdoctoral positions, to industry research labs, and to startups of their own founding — and several are still exploring what comes next and would love to hear from you.
Please join us in celebrating the achievements of these wonderful graduates. We are proud of everything they have accomplished at Berkeley, and we can’t wait to see what they do next!
Continue

Overview of adaptive parallel reasoning.
What if a reasoning model could decide for itself when to decompose and parallelize independent subtasks, how many concurrent threads to spawn, and how to coordinate them based on the problem at hand? We provide a detailed analysis of recent progress in the field of parallel reasoning, especially Adaptive Parallel Reasoning.
Continue
GRASP is a new gradient-based planner for learned dynamics (a “world model”) that makes long-horizon planning practical by (1) lifting the trajectory into virtual states so optimization is parallel across time, (2) adding stochasticity directly to the state iterates for exploration, and (3) reshaping gradients so actions get clean signals while we avoid brittle “state-input” gradients through high-dimensional vision models.
Continue

Understanding the behavior of complex machine learning systems, particularly Large Language Models (LLMs), is a critical challenge in modern artificial intelligence. Interpretability research aims to make the decision-making process more transparent to model builders and impacted humans, a step toward safer and more trustworthy AI. To gain a comprehensive understanding, we can analyze these systems through different lenses: feature attribution, which isolates the specific input features driving a prediction (Lundberg & Lee, 2017; Ribeiro et al., 2022); data attribution, which links model behaviors to influential training examples (Koh & Liang, 2017; Ilyas et al., 2022); and mechanistic interpretability, which dissects the functions of internal components (Conmy et al., 2023; Sharkey et al., 2025).
Continue

An encoder (optical system) maps objects to noiseless images, which noise corrupts into measurements. Our information estimator uses only these noisy measurements and a noise model to quantify how well measurements distinguish objects.
Many imaging systems produce measurements that humans never see or cannot interpret directly. Your smartphone processes raw sensor data through algorithms before producing the final photo. MRI scanners collect frequency-space measurements that require reconstruction before doctors can view them. Self-driving cars process camera and LiDAR data directly with neural networks.
What matters in these systems is not how measurements look, but how much useful information they contain. AI can extract this information even when it is encoded in ways that humans cannot interpret.
Continue
In this post, I’ll introduce a reinforcement learning (RL) algorithm based on an “alternative” paradigm: divide and conquer. Unlike traditional methods, this algorithm is not based on temporal difference (TD) learning (which has scalability challenges), and scales well to long-horizon tasks.

We can do Reinforcement Learning (RL) based on divide and conquer, instead of temporal difference (TD) learning.
Continue
What exactly does word2vec learn, and how? Answering this question amounts to understanding representation learning in a minimal yet interesting language modeling task. Despite the fact that word2vec is a well-known precursor to modern language models, for many years, researchers lacked a quantitative and predictive theory describing its learning process. In our new paper, we finally provide such a theory. We prove that there are realistic, practical regimes in which the learning problem reduces to unweighted least-squares matrix factorization. We solve the gradient flow dynamics in closed form; the final learned representations are simply given by PCA.

Learning dynamics of word2vec. When trained from small initialization, word2vec learns in discrete, sequential steps. Left: rank-incrementing learning steps in the weight matrix, each decreasing the loss. Right: three time slices of the latent embedding space showing how embedding vectors expand into subspaces of increasing dimension at each learning step, continuing until model capacity is saturated.
Continue

