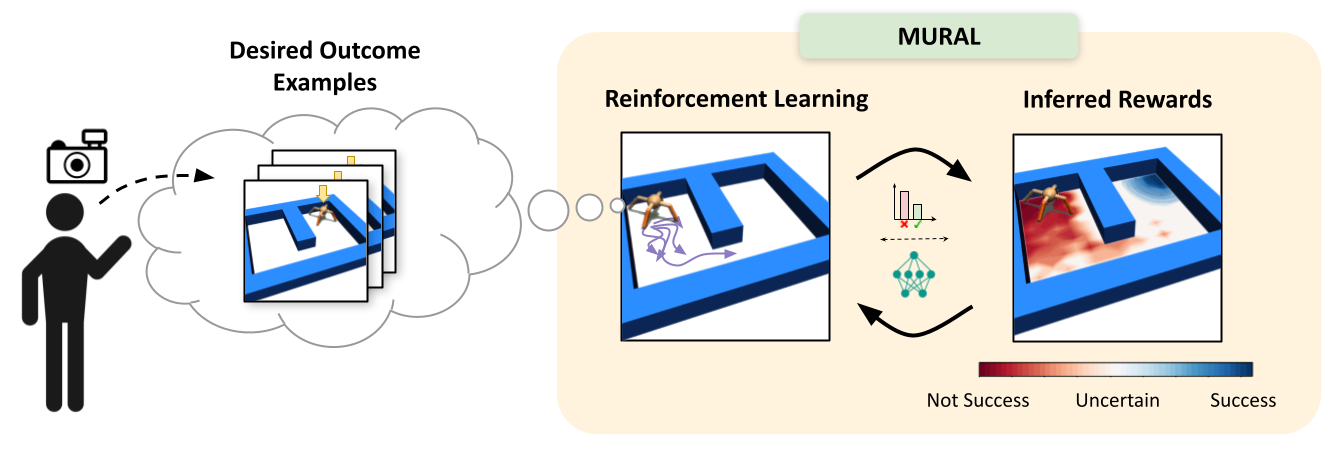
Diagram of MURAL, our method for learning uncertainty-aware rewards for RL. After the user provides a few examples of desired outcomes, MURAL automatically infers a reward function that takes into account these examples and the agent’s uncertainty for each state.
Although reinforcement learning has shown success in domains suchasrobotics, chip placement and playingvideogames, it is usually intractable in its most general form. In particular, deciding when and how to visit new states in the hopes of learning more about the environment can be challenging, especially when the reward signal is uninformative. These questions of reward specification and exploration are closely connected — the more directed and “well shaped” a reward function is, the easier the problem of exploration becomes. The answer to the question of how to explore most effectively is likely to be closely informed by the particular choice of how we specify rewards.
For unstructured problem settings such as robotic manipulation and navigation — areas where RL holds substantial promise for enabling better real-world intelligent agents — reward specification is often the key factor preventing us from tackling more difficult tasks. The challenge of effective reward specification is two-fold: we require reward functions that can be specified in the real world without significantly instrumenting the environment, but also effectively guide the agent to solve difficult exploration problems. In our recent work, we address this challenge by designing a reward specification technique that naturally incentivizes exploration and enables agents to explore environments in a directed way.
Earlier this year, my research group commissioned 6 questions for professional forecasters to predict about AI. Broadly speaking, 2 were on geopolitical aspects of AI and 4 were on future capabilities:
Geopolitical:
How much larger or smaller will the largest Chinese ML experiment be compared to the largest U.S. ML experiment, as measured by amount of compute used?
How much computing power will have been used by the largest non-incumbent (OpenAI, Google, DeepMind, FB, Microsoft), non-Chinese organization?
Future capabilities:
What will SOTA (state-of-the-art accuracy) be on the MATH dataset?
What will SOTA be on the Massive Multitask dataset (a broad measure of specialized subject knowledge, based on high school, college, and professional exams)?
What will be the best adversarially robust accuracy on CIFAR-10?
What will SOTA be on Something Something v2? (A video recognition dataset)
Forecasters output a probability distribution over outcomes for 2022, 2023, 2024, and 2025. They have financial incentives to produce accurate forecasts; the rewards total \$5k per question (\$30k total) and payoffs are (close to) a proper scoring rule, meaning forecasters are rewarded for outputting calibrated probabilities.
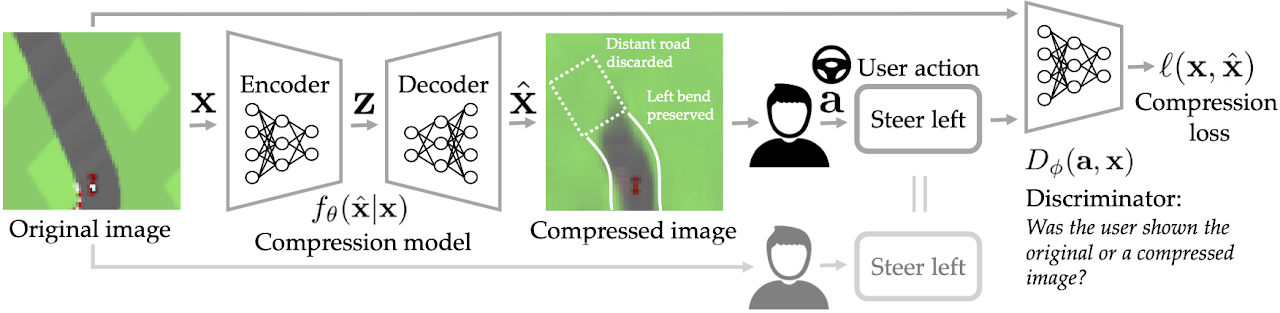
Fig. 1: Given the original image $\mathbf{x}$, we would like to generate a compressed image $\hat{\mathbf{x}}$ such that the user's action $\mathbf{a}$ upon seeing the compressed image is similar to what it would have been had the user seen the original image instead. In a 2D top-down car racing video game with an extremely high compression rate (50%), our compression model learns to preserve bends and discard the road farther ahead.
Imagine remotely operating a Mars rover from a desk on Earth. The low-bandwidth network connection can make it challenging for the teleoperation system to provide the user with high-dimensional observations like images. One approach to this problem is to use data compression to minimize the number of bits that need to be communicated over the network: for example, the rover can compress the pictures it takes on Mars before sending them to the human operator on Earth. Standard lossy image compression algorithms would attempt to preserve the image's appearance. However, at low bitrates, this approach can waste precious bits on information that the user does not actually need in order to perform their current task. For example, when deciding where to steer and how much to accelerate, the user probably only pays attention to a small subset of visual features, such as obstacles and landmarks. Our insight is that we should focus on preserving those features that affect user behavior, instead of features that only affect visual appearance (e.g., the color of the sky). In this post, we outline a pragmatic compression algorithm called PICO that achieves lower bitrates by intentionally allowing reconstructed images to deviate drastically from the visual appearance of their originals, and instead optimizing reconstructions for the downstream tasks that the user wants to perform with them (see Fig. 1).
Along with researchers from Google Brain and OpenAI, we are releasing a paper on Unsolved Problems in ML Safety.
Due to emerging safety challenges in ML, such as those introduced by recent large-scale models, we provide a new roadmap for ML Safety and refine the technical problems that the field needs to address.
As a preview of the paper, in this post we consider a subset of the paper’s directions, namely withstanding hazards (“Robustness”), identifying hazards (“Monitoring”), and steering ML systems (“Alignment”).
Robustness
Robustness research aims to build systems that are less vulnerable to extreme hazards and to adversarial threats. Two problems in robustness are robustness to long tails and robustness to adversarial examples.
Long Tails
Examples of long tail events. First row, left: an ambulance in front of a green light. First row, middle: birds on the road. First row, right: a reflection of a pedestrian. Bottom row, left: a group of people cosplaying. Bottom row, middle: a foggy road. Bottom row, right: a person partly occluded by a board on their back. (Source)
Recent deep neural networks (DNNs) often predict extremely well, but sacrifice interpretability and computational efficiency. Interpretability is crucial in many disciplines, such as science and medicine, where models must be carefully vetted or where interpretation is the goal itself. Moreover, interpretable models are concise and often yield computational efficiency.
How do humans become so skillful? Well, initially we are not, but from infancy, we discover and practice increasingly complex skills through self-supervised play. But this play is not random - the child development literature suggests that infants use their prior experience to conduct directed exploration of affordances like movability, suckability, graspability, and digestibility through interaction and sensory feedback. This type of affordance directed exploration allows infants to learn both what can be done in a given environment and how to do it. Can we instantiate an analogous strategy in a robotic learning system?
On the left we see videos from a prior dataset collected with a robot accomplishing various tasks such as drawer opening and closing, as well as grasping and relocating objects. On the right we have a lid that the robot has never seen before. The robot has been granted a short period of time to practice with the new object, after which it will be given a goal image and tasked with making the scene match this image. How can the robot rapidly learn to manipulate the environment and grasp this lid without any external supervision?
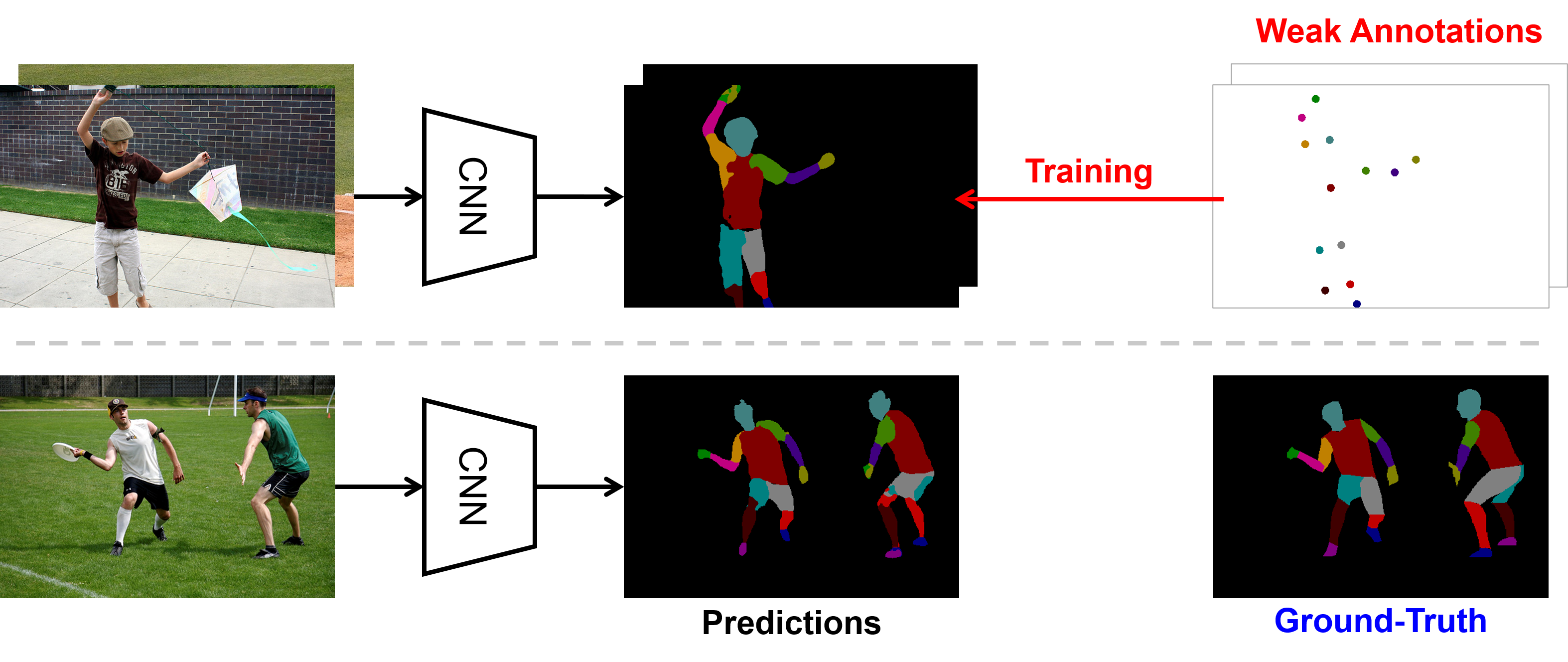
We consider a problem: Can a machine learn from a few labeled pixels to predict every pixel in a new image?
This task is extremely challenging (see Fig. 1) as a single body part could contain visually distinctive areas
(e.g. head consists of eyes, noses and mouths); different body parts might look similar and undistinguishable
(e.g., upper arms v.s. lower arms). It could be even more difficult if we do not provide any precise location
but only the occurrence of body parts in the image. This problem is dubbed weakly-supervised segmentation, where
the goal is to classify every pixel into semantic categories using only partial / weak supervision. There are many
forms of weak annotations which are cheap but not perfect, e.g. image-level tags, bounding boxes, points and scribbles.
Recent years have demonstrated the potential of deep multi-agent reinforcement
learning (MARL) to train groups of AI agents that can collaborate to solve complex
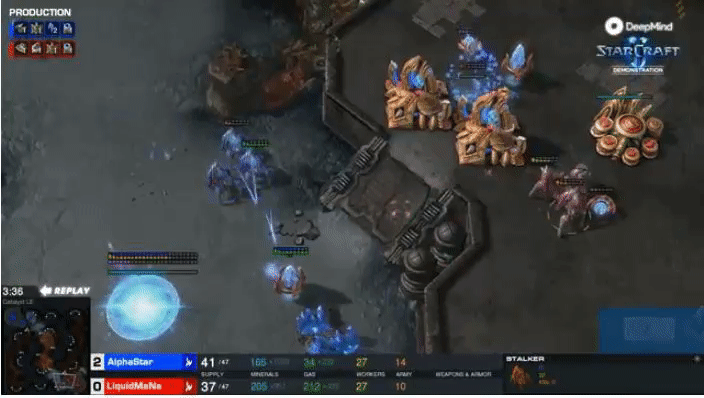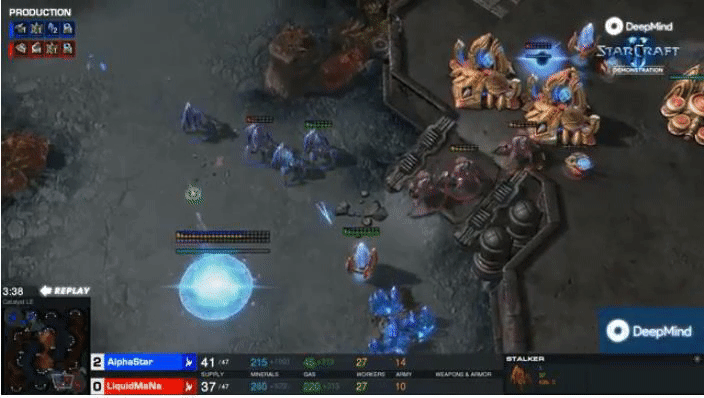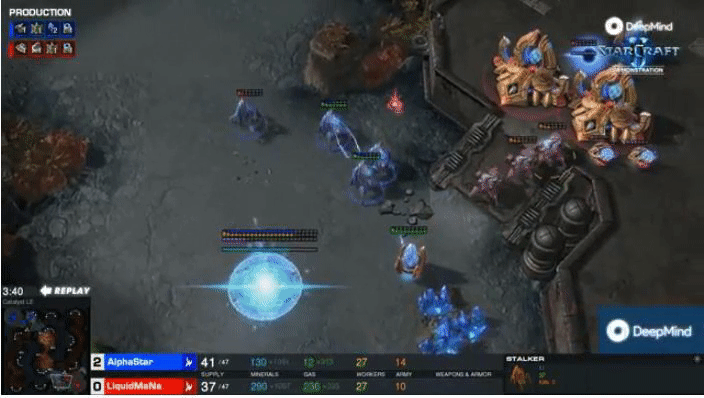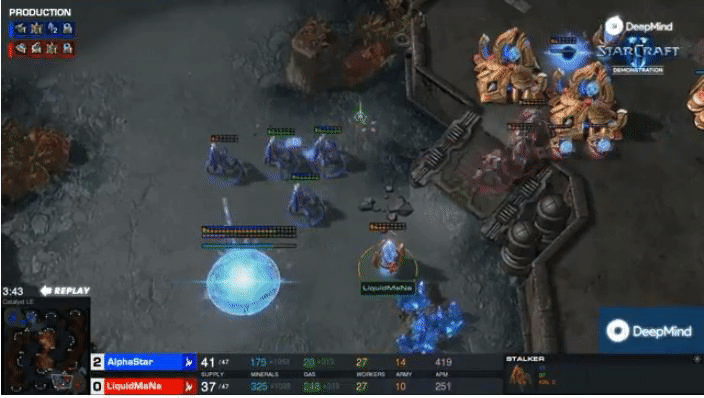
tasks - for instance, AlphaStar achieved professional-level performance in the
Starcraft II video game, and OpenAI Five defeated the world champion in Dota2.
These successes, however, were powered by huge swaths of computational resources;
tens of thousands of CPUs, hundreds of GPUs, and even TPUs were used to collect and train on
a large volume of data. This has motivated the academic MARL community to develop
MARL methods which train more efficiently.
DeepMind's AlphaStar attained professional level performance in StarCraft II, but required enormous amounts of
computational power to train.
Research in developing more efficient and effective MARL algorithms has focused on off-policy methods - which store and re-use data for multiple policy updates - rather than on-policy algorithms, which use newly collected training data before each update to the agents’ policies. This is largely due to the common belief that off-policy algorithms are much more sample-efficient than on-policy methods.
In this post, we outline our recent publication in which we re-examine many of these assumptions about on-policy algorithms. In particular, we analyze the performance of PPO, a popular single-agent on-policy RL algorithm, and demonstrate that with several simple modifications, PPO achieves strong performance in 3 popular MARL benchmarks while exhibiting a similar sample efficiency to popular off-policy algorithms in the majority of scenarios. We study the impact of these modifications through ablation studies and suggest concrete implementation and tuning practices which are critical for strong performance. We refer to PPO with these modifications as Multi-Agent PPO (MAPPO).
TL;DR: We are launching a NeurIPS competition and benchmark called BASALT: a
set of Minecraft environments and a human evaluation protocol that we hope will
stimulate research and investigation into solving tasks with no pre-specified
reward function, where the goal of an agent must be communicated through
demonstrations, preferences, or some other form of human feedback. Sign up
to participate in the
competition!
Reinforcement learning (RL) has been used successfully for solving tasks which
have a well defined reward function – think AlphaZero for Go, OpenAI Five for
Dota, or AlphaStar for StarCraft. However, in many practical situations you
don’t have a well defined reward function. Even a task as seemingly
straightforward as cleaning a room has many subtle cases: should a business
card with a piece of gum be thrown away as trash, or might it have sentimental
value? Should the clothes on the floor be washed, or returned to the
closet? Where are notebooks supposed to be stored? Even when these aspects of
a task have been clarified, translating it into a reward is non-trivial: if you
provide rewards every time you sweep the trash, then the agent might dump the
trash back out so that it can sweep it up again.1
Alternatively, we can try to learn a reward function from human feedback about
the behavior of the agent. For example, Deep RL from Human Preferences
learns a reward function from pairwise comparisons of video clips of the
agent’s behavior. Unfortunately, however, this approach can be very costly:
training a MuJoCo Cheetah to run forward requires a human to provide 750
comparisons.
Instead, we propose an algorithm that can learn a policy without any human
supervision or reward function, by using information implicitly available in
the state of the world. For example, we learn a policy that balances this
Cheetah on its front leg from a single state in which it is balancing.
See timestamp 31:47 in the linked podcast. Transcript: ‘One of the examples that I give is my friend and collaborator, Tom Griffiths. When his daughter was really young, she had this toy brush and pan, and she swept up some stuff on the floor and put it in the trash. And he praised her, like “Oh, wow, good job. You swept that really well.” And the daughter was very proud. And then without missing a beat, she dumps the trash back out onto the floor in order to sweep it up a second time and get the same praise a second time.’ ↩


 Instead, we propose an algorithm that can learn a policy without any human
supervision or reward function, by using information implicitly available in
the state of the world. For example, we learn a policy that balances this
Cheetah on its front leg from a single state in which it is balancing.
Instead, we propose an algorithm that can learn a policy without any human
supervision or reward function, by using information implicitly available in
the state of the world. For example, we learn a policy that balances this
Cheetah on its front leg from a single state in which it is balancing.