How do humans become so skillful? Well, initially we are not, but from infancy, we discover and practice increasingly complex skills through self-supervised play. But this play is not random - the child development literature suggests that infants use their prior experience to conduct directed exploration of affordances like movability, suckability, graspability, and digestibility through interaction and sensory feedback. This type of affordance directed exploration allows infants to learn both what can be done in a given environment and how to do it. Can we instantiate an analogous strategy in a robotic learning system?
On the left we see videos from a prior dataset collected with a robot accomplishing various tasks such as drawer opening and closing, as well as grasping and relocating objects. On the right we have a lid that the robot has never seen before. The robot has been granted a short period of time to practice with the new object, after which it will be given a goal image and tasked with making the scene match this image. How can the robot rapidly learn to manipulate the environment and grasp this lid without any external supervision?
To do so, we face several challenges. When a robot is dropped in a new environment, it must be able to use its prior knowledge to think of potentially useful behaviors that the environment affords. Then, the robot has to be able to actually practice these behaviors informatively. To now improve itself in the new environment, the robot must then be able to evaluate its own success somehow without an externally provided reward.
If we can overcome these challenges reliably, we open the door for a powerful cycle in which our agents use prior experience to collect high quality interaction data, which then grows their prior experience even further, continuously enhancing their potential utility!
VAL: Visuomotor Affordance Learning
Our method, Visuomotor Affordance Learning, or VAL, addresses these challenges. In VAL, we begin by assuming access to a prior dataset of robots demonstrating affordances in various environments. From here, VAL enters an offline phase which uses this information to learn 1) a generative model for imagining useful affordances in new environments, 2) a strong offline policy for effective exploration of these affordances, and 3) a self-evaluation metric for improving this policy. Finally, VAL is ready for it’s online phase. The agent is dropped in a new environment and can now use these learned capabilities to conduct self-supervised finetuning. The whole framework is illustrated in the figure below. Next, we will go deeper into the technical details of the offline and online phase.
VAL: Offline Phase
Given a prior dataset demonstrating the affordances of various environments, VAL digests this information in three offline steps: representation learning to handle high dimensional real world data, affordance learning to enable self-supervised practice in unknown environments, and behavior learning to attain a high performance initial policy which accelerates online learning efficiency.
1. First, VAL learns a low representation of this data using a Vector Quantized Variational Auto-encoder or VQVAE. This process reduces our 48x48x3 images into a 144 dimensional latent space.
Distances in this latent space are meaningful, paving the way for our crucial mechanism of self-evaluating success. Given the current image s and goal image g, we encode both into the latent space, and threshold their distance to obtain a reward.
Later on, we will also use this representation as the latent space for our policy and Q function.
2. Next, VAL learn an affordance model by training a PixelCNN in the latent space to the learn the distribution of reachable states conditioned on an image from the environment. This is done by maximizing the likelihood of the data, $p(s_n | s_0)$. We use this affordance model for directed exploration and for relabeling goals.
The affordance model is illustrated in the figure right. On the bottom left of the figure, we see that the conditioning image contains a pot, and the decoded latent goals on the upper right show the lid in different locations. These coherent goals will allow the robot to perform coherent exploration.
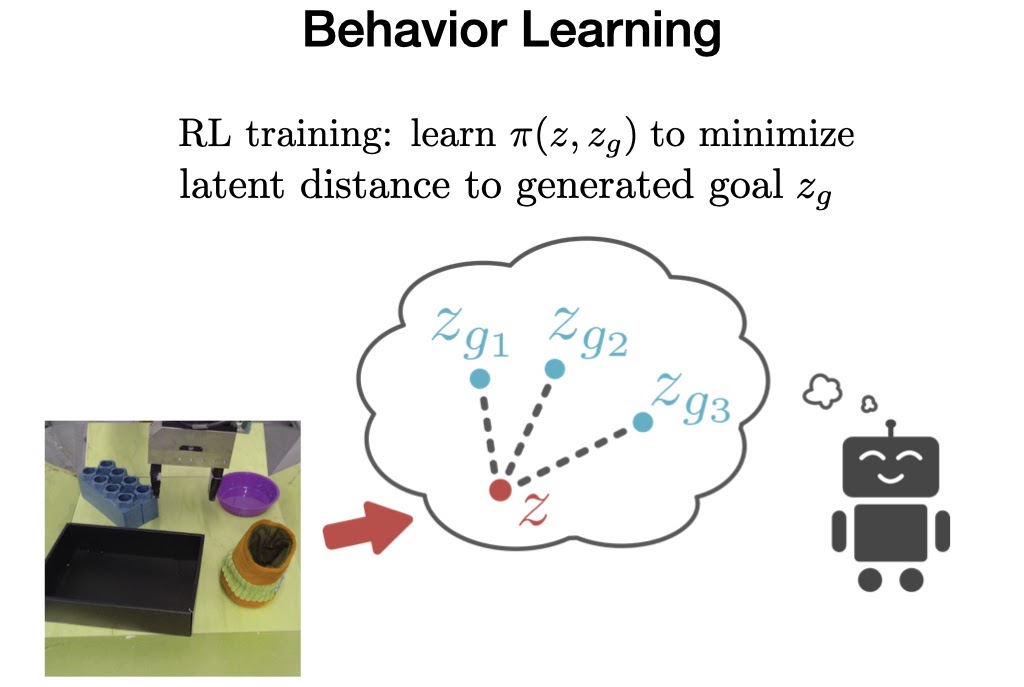
3. Last in the offline phase, VAL must learn behaviors from the offline data, which it can then improve upon later with extra online, interactive data collection.
To accomplish this, we train a goal conditioned policy on the prior dataset using Advantage Weighted Actor Critic, an algorithm specifically designed for training offline and being amenable to online fine-tuning.
VAL: Online Phase
Now, when VAL is placed in an unseen environment, it uses its prior knowledge to imagine visual representations of useful affordances, collects helpful interaction data by trying to achieve these affordances, updates its parameters using its self-evaluation metric, and repeats the process all over again.
In this real example, on the left we see the initial state of the environment, which affords opening the drawer as well as other tasks.
In step 1, the affordance model samples a latent goal. By decoding the goal (using the VQVAE decoder, which is never actually used during RL because we operate entirely in the latent space), we can see the affordance is to open a drawer.
In step 2, we roll out the trained policy with the sampled goal. We see it successfully opens the drawer, in fact going too far and pulling the drawer all the way out. But this provides extremely useful interaction for the RL algorithm to further fine-tune on and perfect its policy.
After online finetuning is complete, we can now evaluate the robot on its ability to achieve the corresponding unseen goal images for each environment.
Real World Evaluation
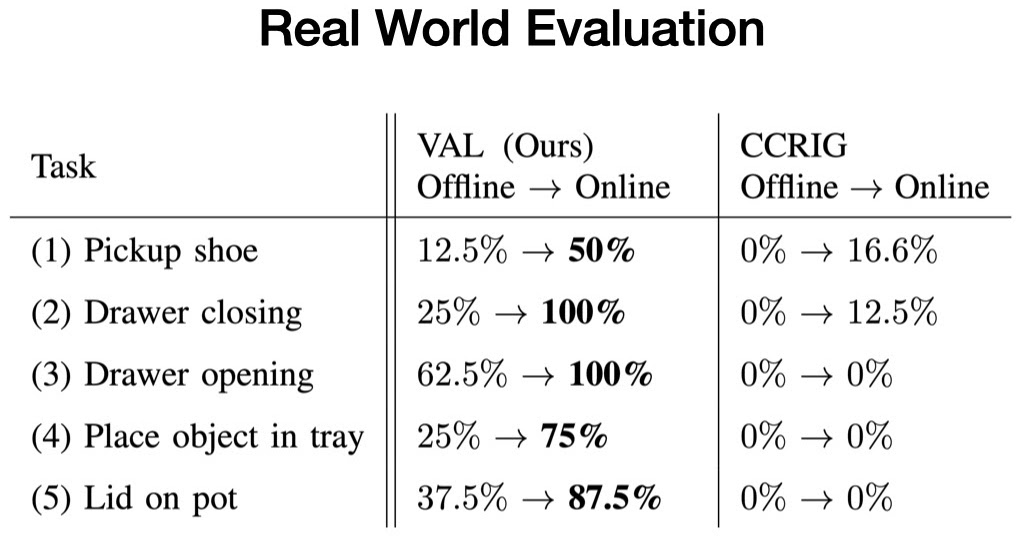
We evaluate our method in five real-world test environments, and assess VAL on its ability to achieve a specific task the environment affords before and after five minutes of unsupervised fine-tuning.
Each test environment consists of at least one unseen interaction object, and two randomly sampled distractor objects. For instance, while there is opening and closing drawers in the training data, the new drawers have unseen handles.
In every case, we begin with the offline trained policy, which solves the task inconsistently. Then, we collect more experience using our affordance model to sample goals. Finally, we evaluate the fine-tuned policy, which consistently solves the task.
We find that in each of these environments, VAL consistently demonstrates effective zero-shot generalization after offline training, followed by rapid improvement with its affordance-directed fine-tuning scheme. Meanwhile, prior self-supervised methods barely improve upon poor zero-shot performance in these new environments. These exciting results illustrate the potential that approaches like VAL possess for enabling robots to successfully operate far beyond the limited factory setting in which they are used to now.
Our dataset of 2,500 high quality robot interaction trajectories, covering 20 drawer handles, 20 pot handles, 60 toys, and 60 distractor objects, is now publicly available on our website.
Simulated Evaluation and Code
For further analysis, we run VAL in a procedurally generated, multi-task environment with visual and dynamic variation. Which objects are in the scene, their colors, and their positions are randomized per environment. The agent can use handles to open drawers, grasp objects to relocate them, press buttons to unlock compartments, and so on.
The robot is given a prior dataset spanning various environments, and is evaluated on its ability to fine-tune on the following test environments.
Again, given a single off-policy dataset, our method quickly learns advanced manipulation skills including grasping, drawer opening, re-positioning, and tool usage for a diverse set of novel objects.
The environments and algorithm code are available; please see our code repository.
Future Work
Like deep learning in domains such as computer vision and natural language processing which have been driven by large datasets and generalization, robotics will likely require learning from a similar scale of data. Because of this, improvements in offline reinforcement learning will be critical for enabling robots to take advantage of large prior datasets. Furthermore, these offline policies will need either rapid non-autonomous finetuning or entirely autonomous finetuning for real world deployment to be feasible. Lastly, once robots are operating on their own, we will have access to a continuous stream of new data, stressing both the importance and value of lifelong learning algorithms.
This post is based on the paper “What Can I Do Here? Learning New Skills by Imagining Visual Affordances”, which was presented at the International Conference on Robotics and Automation (ICRA), 2021. You can see results on our website, and we provide code to to reproduce our experiments.