A remarkable characteristic of human intelligence is our ability to learn tasks
quickly. Most humans can learn reasonably complex skills like tool-use and
gameplay within just a few hours, and understand the basics after only a few
attempts. This suggests that data-efficient learning may be a meaningful part
of developing broader intelligence.
On the other hand, Deep Reinforcement Learning (RL) algorithms can achieve
superhuman performance on games like Atari, Starcraft, Dota, and Go, but
require large amounts of data to get there. Achieving superhuman performance on
Dota took over 10,000 human years of gameplay. Unlike simulation, skill
acquisition in the real-world is constrained to wall-clock time. In order to
see similar breakthroughs to AlphaGo in real-world settings, such as robotic
manipulation and autonomous vehicle navigation, RL algorithms need to be
data-efficient — they need to learn effective policies within a reasonable
amount of time.
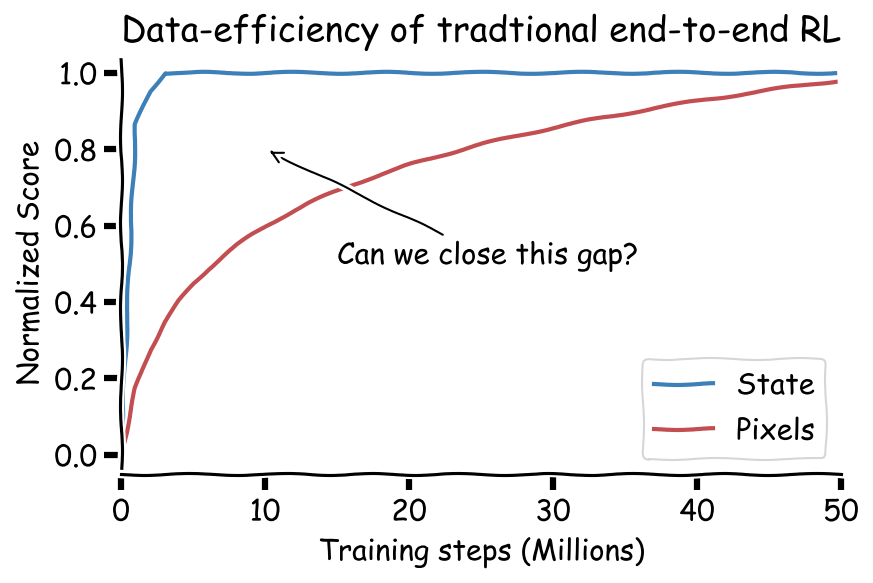
To date, it has been commonly assumed that RL operating on coordinate state is
significantly more data-efficient than pixel-based RL. However, coordinate
state is just a human crafted representation of visual information. In
principle, if the environment is fully observable, we should also be able to
learn representations that capture the state.
Continue
Many neural network architectures that underlie various artificial intelligence systems today bear an interesting similarity to the early computers a century ago.
Just as early computers were specialized circuits for specific purposes like solving linear systems or cryptanalysis, so too does the trained neural network generally function as a specialized circuit for performing a specific task, with all parameters coupled together in the same global scope.
One might naturally wonder what it might take for learning systems to scale in complexity in the same way as programmed systems have.
And if the history of how abstraction enabled computer science to scale gives any indication, one possible place to start would be to consider what it means to build complex learning systems at multiple levels of abstraction, where each level of learning is the emergent consequence of learning from the layer below.
This post discusses our recent paper that introduces a framework for societal decision-making, a perspective on reinforcement learning through the lens of a self-organizing society of primitive agents.
We prove the optimality of an incentive mechanism for engineering the society to optimize a collective objective.
Our work also provides suggestive evidence that the local credit assignment scheme of the decentralized reinforcement learning algorithms we develop to train the society facilitates more efficient transfer to new tasks.
Continue



In the last decade, one of the biggest drivers for success in machine learning has arguably been the rise of high-capacity models such as neural networks along with large datasets such as ImageNet to produce accurate models. While we have seen deep neural networks being applied to success in reinforcement learning (RL) in domains such as robotics, poker, board games, and team-based video games, a significant barrier to getting these methods working on real-world problems is the difficulty of large-scale online data collection. Not only is online data collection time-consuming and expensive, it can also be dangerous in safety-critical domains such as driving or healthcare. For example, it would be unreasonable to allow reinforcement learning agents to explore, make mistakes, and learn while controlling an autonomous vehicle or treating patients in a hospital. This makes learning from pre-collected experience enticing, and we are fortunate in that many of these domains, there already exist large datasets for applications such as self-driving cars, healthcare, or robotics. Therefore, the ability for RL algorithms to learn offline from these datasets (a setting referred to as offline or batch RL) has an enormous potential impact in shaping the way we build machine learning systems for the future.
Continue
The World is Continuously Varying
Imagine we want to train a self-driving car in New York so that we can take it
all the way to Seattle without tediously driving it for over 48 hours. We hope
our car can handle all kinds of environments on the trip and send us safely to
the destination. We know that road conditions and views can be very different.
It is intuitive to simply collect road data of this trip, let the car learn
from every possible condition, and hope it becomes the perfect self-driving car
for our New York to Seattle trip. It needs to understand the traffic and
skyscrapers in big cities like New York and Chicago, more unpredictable weather
in Seattle, mountains and forests in Montana, and all kinds of country views,
farmlands, animals, etc. However, how much data is enough? How many cities
should we collect data from? How many weather conditions should we consider? We
never know, and these questions never stop.
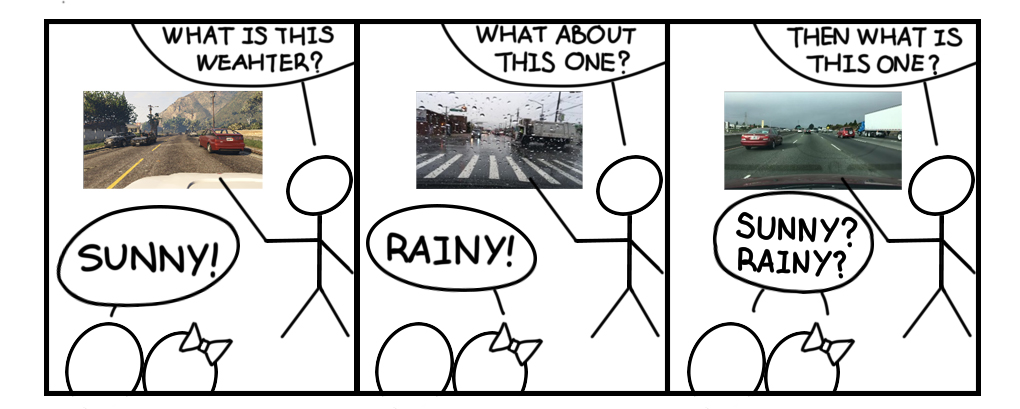
Figure 1: Domains boundaries are rarely clear. Therefore, it is hard to set up
definite domain descriptions for all possible domains.
Continue

Human thumb next to our OmniTact sensor, and a US penny for scale.
Touch has been shown to be important for dexterous manipulation in
robotics. Recently, the GelSight sensor has caught significant interest
for learning-based robotics due to its low cost and rich signal. For example,
GelSight sensors have been used for learning inserting USB cables (Li et al,
2014), rolling a die (Tian et al. 2019) or grasping objects (Calandra
et al. 2017).
The reason why learning-based methods work well with GelSight sensors is that
they output high-resolution tactile images from which a variety of features
such as object geometry, surface texture, normal and shear forces can be
estimated that often prove critical to robotic control. The tactile images
can be fed into standard CNN-based computer vision pipelines allowing the use
of a variety of different learning-based techniques: In Calandra et al.
2017 a grasp-success classifier is trained on GelSight data collected in
self-supervised manner, in Tian et al. 2019 Visual Foresight, a
video-prediction-based control algorithm is used to make a robot roll a die
purely based on tactile images, and in Lambeta et al. 2020 a model-based
RL algorithm is applied to in-hand manipulation using GelSight images.
Unfortunately applying GelSight sensors in practical real-world scenarios is
still challenging due to its large size and the fact that it is only sensitive
on one side. Here we introduce a new, more compact tactile sensor design based
on GelSight that allows for omnidirectional sensing, i.e. making the sensor
sensitive on all sides like a human finger, and show how this opens up new
possibilities for sensorimotor learning. We demonstrate this by teaching a
robot to pick up electrical plugs and insert them purely based on tactile
feedback.
Continue


Humans manipulate 2D deformable structures such as fabric on a daily basis,
from putting on clothes to making beds. Can robots learn to perform similar
tasks? Successful approaches can advance applications such as dressing
assistance for senior care, folding of laundry, fabric upholstery, bed-making,
manufacturing, and other tasks. Fabric manipulation is challenging, however,
because of the difficulty in modeling system states and dynamics, meaning that
when a robot manipulates fabric, it is hard to predict the fabric’s resulting
state or visual appearance.
In this blog post, we review four recent papers from two research labs (Pieter
Abbeel’s and Ken Goldberg’s) at Berkeley AI Research (BAIR) that
investigate the following hypothesis: is it possible to employ learning-based
approaches to the problem of fabric manipulation?
We demonstrate promising results in support of this hypothesis by using a
variety of learning-based methods with fabric simulators to train smoothing
(and even folding) policies in simulation. We then perform sim-to-real transfer
to deploy the policies on physical robots. Examples of the learned policies in
action are shown in the GIFs above.
We show that deep model-free methods trained from exploration or from
demonstrations work reasonably well for specific tasks like smoothing, but it
is unclear how well they generalize to related tasks such as folding. On the
other hand, we show that deep model-based methods have more potential for
generalization to a variety of tasks, provided that the learned models are
sufficiently accurate. In the rest of this post, we summarize the papers,
emphasizing the techniques and tradeoffs in each approach.
Continue
This post is cross-listed on the CMU ML blog.
The history of machine learning has largely been a story of increasing
abstraction. In the dawn of ML, researchers spent considerable effort
engineering features. As deep learning gained popularity, researchers then
shifted towards tuning the update rules and learning rates for their
optimizers. Recent research in meta-learning has climbed one level of
abstraction higher: many researchers now spend their days manually constructing
task distributions, from which they can automatically learn good optimizers.
What might be the next rung on this ladder? In this post we introduce theory
and algorithms for unsupervised meta-learning, where machine learning
algorithms themselves propose their own task distributions. Unsupervised
meta-learning further reduces the amount of human supervision required to solve
tasks, potentially inserting a new rung on this ladder of abstraction.
Continue

Robots have been useful in environments that can be carefully controlled, such
as those commonly found in industrial settings (e.g. assembly lines). However,
in unstructured settings like the home, we need robotic systems that are
adaptive to the diversity of the real world.
Continue

The interpretability of neural networks is becoming increasingly necessary, as
deep learning is being adopted in settings where accurate and justifiable
predictions are required. These applications range from finance to medical
imaging. However, deep neural networks are notorious for a lack of
justification. Explainable AI (XAI) attempts to bridge this divide between
accuracy and interpretability, but as we explain below, XAI justifies
decisions without interpreting the model directly.
Continue

Quadruped robot learning locomotion skills by imitating a dog.
Whether it’s a dog chasing after a ball, or a monkey swinging through the
trees, animals can effortlessly perform an incredibly rich repertoire of agile
locomotion skills. But designing controllers that enable legged robots to
replicate these agile behaviors can be a very challenging task. The superior
agility seen in animals, as compared to robots, might lead one to wonder: can
we create more agile robotic controllers with less effort by directly imitating
animals?
In this work, we present a framework for learning robotic locomotion skills by
imitating animals. Given a reference motion clip recorded from an animal (e.g.
a dog), our framework uses reinforcement learning to train a control policy
that enables a robot to imitate the motion in the real world. Then, by simply
providing the system with different reference motions, we are able to train a
quadruped robot to perform a diverse set of agile behaviors, ranging from fast
walking gaits to dynamic hops and turns. The policies are trained primarily in
simulation, and then transferred to the real world using a latent space
adaptation technique, which is able to efficiently adapt a policy using only a
few minutes of data from the real robot.
Continue