In many tasks in machine learning, it is common to want to answer questions
given fixed, pre-collected datasets. In some applications, however, we are not
given data a priori; instead, we must collect the data we require to answer the
questions of interest. This situation arises, for example, in environmental
contaminant monitoring and census-style surveys. Collecting the data ourselves
allows us to focus our attention on just the most relevant sources of
information. However, determining which of these sources of information will
yield useful measurements can be difficult. Furthermore, when data is collected
by a physical agent (e.g. robot, satellite, human, etc.) we must plan our
measurements so as to reduce costs associated with the motion of the agent over
time. We call this abstract problem embodied adaptive sensing.
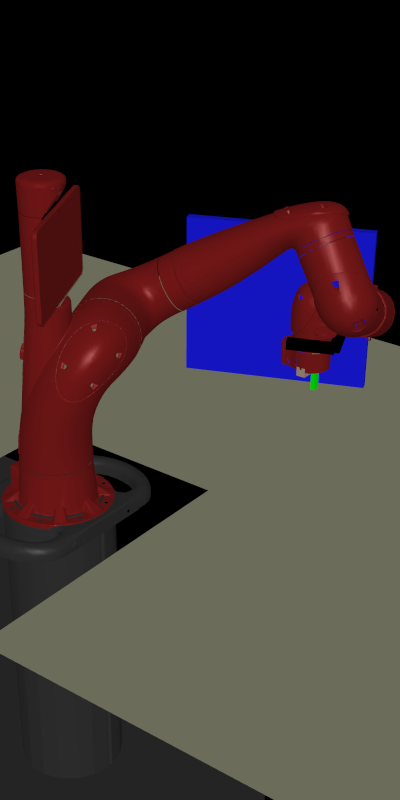
We introduce a new approach to the embodied adaptive sensing problem, in which a
robot must traverse its environment to identify locations or items of interest.
Adaptive sensing encompasses many well-studied problems in robotics, including
the rapid identification of accidental contamination leaks and radioactive
sources, and finding individuals in search and rescue missions. In such
settings, it is often critical to devise a sensing trajectory that returns a
correct solution as quickly as possible.
Top left: image of a 3D cube. Top right: example depth image, with darker points
representing areas closer to the camera (source: Wikipedia). Next two
rows: examples of depth and RGB image pairs for grasping objects in a bin. Last
two rows: similar examples for bed-making.
This post explores two independent innovations and the potential for combining
them in robotics. Two years before the AlexNet results on ImageNet
were released in 2012, Microsoft rolled out the Kinect for the X-Box. This class
of low-cost depth sensors emerged just as Deep Learning boosted
Artificial Intelligence by accelerating performance of hyper-parametric function
approximators leading to surprising advances in image classification,
speech recognition, and language translation. Today, Deep Learning is
also showing promise for end-to-end learning of playing video games and
performing robotic manipulation tasks.
For robot perception, convolutional neural networks (CNNs), such as
VGG or ResNet, with three RGB color channels have become standard. For
robotics and computer vision tasks, it is common to borrow one of these
architectures (along with pre-trained weights) and then to perform transfer
learning or fine-tuning on task-specific data. But in some tasks, knowing
the colors in an image may provide only limited benefits. Consider training a
robot to grasp novel, previously unseen objects. It may be more important to
understand the geometry of the environment rather than colors and textures. The
physical process of manipulation — controlling one or more objects by applying
forces through contact — depends on object geometry, pose, and other factors
which are largely color-invariant. When you manipulate a pen with your hand, for
instance, you can often move it seamlessly without looking at the actual pen, so
long as you have a good understanding of the location and orientation of contact
points. Thus, before proceeding, one might ask: does it makes sense to use
color images?
There is an alternative: depth images. These are single-channel grayscale
images that measure depth values from the camera, and give us invariance to the
colors of objects within an image. We can also use depth to “filter” points
beyond a certain distance which can remove background noise, as we demonstrate
later with robot bed-making. Examples of paired depth and real images are shown
above.
In this post, we consider the potential for combining depth images and deep
learning in the context of three ongoing projects in the UC Berkeley
AUTOLab: Dex-Net for robot grasping, segmenting objects in heaps, and robot
bed-making.
Simulated characters imitating skills from YouTube videos.
Whether it’s everyday tasks like washing our hands or stunning feats of
acrobatic prowess, humans are able to learn an incredible array of skills by
watching other humans. With the proliferation of publicly available video data
from sources like YouTube, it is now easier than ever to find video clips of
whatever skills we are interested in. A staggering 300 hours of videos are
uploaded to YouTube every minute. Unfortunately, it is still very challenging
for our machines to learn skills from this vast volume of visual data. Most
imitation learning approaches require concise representations, such as those
recorded from motion capture (mocap). But getting mocap data can be quite a
hassle, often requiring heavy instrumentation. Mocap systems also tend to be
restricted to indoor environments with minimal occlusion, which can limit the
types of skills that can be recorded. So wouldn’t it be nice if our agents can
also learn skills by watching video clips?
In this work, we present a framework for learning skills from videos (SFV). By
combining state-of-the-art techniques in computer vision and reinforcement
learning, our system enables simulated characters to learn a diverse
repertoire of skills from video clips. Given a single monocular video of an
actor performing some skill, such as a cartwheel or a backflip, our characters
are able to learn policies that reproduce that skill in a physics simulation,
without requiring any manual pose annotations.
We want to build agents that can accomplish arbitrary goals in unstructured
complex environments, such as a personal robot that can perform household
chores. A promising approach is to use deep reinforcement learning, which is a
powerful framework for teaching agents to maximize a reward function. However,
the typical reinforcement learning paradigm involves training an agent to solve
an individual task with a manually designed reward. For example, you might train
a robot to set a dinner table by designing a reward function based on the
distance between each plate or utensil and its goal location. This setup
requires a person to design the reward function for each task, as well as extra
systems like object detectors, which can be expensive and brittle. Moreover, if
we want machines that can perform a large repertoire of chores, we would have to
repeat this RL training procedure on each new task.
While designing reward functions and setting up sensors
(door angle measurement, object detectors, etc.) may be
easy in simulation, it quickly becomes impractical in
the real world (right image).
We train agents to solve various tasks from
vision without extra instrumentation. The top row shows goal images and the
bottom row shows our policies reaching those goals.
In this post, we discuss reinforcement learning algorithms that can be used to
learn multiple different tasks simultaneously, without additional human
supervision. For an agent to acquire skills without human intervention, it must
be able to set goals for itself, interact with the environment, and evaluate
whether it has achieved its goals to improve its behavior, all from raw
observations such as images without manually engineering extra components like
object detectors. We introduce a system that sets abstract goals and
autonomously learns to achieve those goals. We then show that we can use these
autonomously learned skills to perform a variety of user-specified goals, such
as pushing objects, grasping objects, and opening doors, without any additional
learning. Lastly, we demonstrate that our method is efficient enough to work in
the real world on a Sawyer robot. The robot learns to set and achieve goals
involving pushing an object to a specific location, with only images as the
input to the system.
In this post, we demonstrate how deep reinforcement learning (deep RL) can be
used to learn how to control dexterous hands for a variety of manipulation
tasks. We discuss how such methods can learn to make use of low-cost hardware,
can be implemented efficiently, and how they can be complemented with techniques
such as demonstrations and simulation to accelerate learning.
An earlier version of this post was published on Off the Convex
Path. It is reposted here with the
author’s permission.
In the last few years, deep learning practitioners have proposed a litany of
different sequence models. Although recurrent neural networks were once the
tool of choice, now models like the autoregressive
Wavenet or the
Transformer
are replacing RNNs on a diverse set of tasks. In this post, we explore the
trade-offs between recurrent and feed-forward models. Feed-forward models can
offer improvements in training stability and speed, while recurrent models are
strictly more expressive. Intriguingly, this added expressivity does not seem to
boost the performance of recurrent models. Several groups have shown
feed-forward networks can match the results of the best recurrent models on
benchmark sequence tasks. This phenomenon raises an interesting question for
theoretical investigation:
When and why can feed-forward networks replace recurrent neural networks
without a loss in performance?
We discuss several proposed answers to this question and highlight our
recent work that offers an explanation in
terms of a fundamental stability property.
Learning a new skill by observing another individual, the ability to imitate, is
a key part of intelligence in human and animals. Can we enable a robot to do the
same, learning to manipulate a new object by simply watching a human
manipulating the object just as in the video below?
The robot learns to place the peach into the red bowl after watching the human
do so.
We are excited by the interest and excitement generated by our BDD100K dataset.
Our data release and blog post were covered in an unsolicited article by
the UC Berkeley newspaper, the Daily Cal, which was then picked up by other news
services without our prompting or intervention. The paper describing this
dataset is under review at the ECCV 2018 conference, and we followed the rules
of that conference (as communicated to us by the Program Chairs in prompt email
response when we asked for clarification following the reporter’s request; the
ECCV PC’s replied that ECCV follows CVPR’s long-standing policy). We thus
declined to speak to the reporters after they reached out to us. We did not, and
have not, communicated with any media outlets regarding this story.
While the Daily Cal article was accurate; unfortunately, other media outlets who
followed in reporting the story made claims that were attributed to us
incorrectly, and which do not represent our view. In particular, several media
outlets attributed to us a claim that the BDD100K dataset was “800 times” bigger
than other industrial datasets, specifically mentioning Baidu’s ApolloScape.
While it is true our dataset does contain more raw images than other datasets,
including Baidu’s, the stated claim is misleading and we did not put that line
or anything like it in a paper, blog post, or spoken comment to anyone. It
appears that some reporters(s) viewed the data in tables in our paper and came
up with this conclusory comment themselves as it made an exciting headline, yet
attributed it to us. In fact, it is inappropriate in our view to summarize the
difference between our dataset and Baidu’s in a single comment that ours is 800x
larger. Comparing the number of raw images directly is not the most appropriate
way to compare these types of datasets.
Importantly, different datasets focus on different aspects of the autonomous
driving challenge. Our dataset is crowd-sourced, and covers a very large area
and diverse visual phenomena (indeed significantly more diverse than previous
efforts, in our view), but it is very clearly limited to monocular RGB image
data and associated mobile device metadata. Other dataset collection efforts are
complementary in our view. Baidu’s, KITTI, and CityScapes each contain important
additional sensing modalities and are collected with fully calibrated apparatus
including actuation channels. (The dataset from Mapillary is also notable, and
similar to ours in being diverse, crowd-sourced, and densely annotated, but
differs in that we include video and dynamic metadata relevant to driving
control.) We look forward to projects at Berkeley and elsewhere that leverage
both BDD100K and these other datasets as the research community brings the
potential of autonomous driving to reality.
TL;DR, we released the largest and most diverse driving video dataset with rich
annotations called BDD100K. You can access the data for research now at http://bdd-data.berkeley.edu. We have
recently released an arXiv
report on it. And there is still time to participate in our CVPR 2018 challenges!
Machine learning systems trained to minimize prediction error may often exhibit
discriminatory behavior based on sensitive characteristics such as race and
gender. One reason could be due to historical bias in the data. In various
application domains including lending, hiring, criminal justice, and
advertising, machine learning has been criticized for its potential to harm
historically underrepresented or disadvantaged groups.
In this post, we talk about our recent work on aligning decisions made by
machine learning with long term social welfare goals. Commonly, machine learning
models produce a score that summarizes information about an individual in
order to make decisions about them. For example, a credit score summarizes an
individual’s credit history and financial activities in a way that informs the
bank about their creditworthiness. Let us continue to use the lending setting as
a running example.