Update 06/18/2018: please also check our follow-up blog post after reading this.
TL;DR, we released the largest and most diverse driving video dataset with rich annotations called BDD100K. You can access the data for research now at http://bdd-data.berkeley.edu. We have recently released an arXiv report on it. And there is still time to participate in our CVPR 2018 challenges!
Large-scale, Diverse, Driving, Video: Pick Four
Autonomous driving is poised to change the life in every community. However, recent events show that it is not clear yet how a man-made perception system can avoid even seemingly obvious mistakes when a driving system is deployed in the real world. As computer vision researchers, we are interested in exploring the frontiers of perception algorithms for self-driving to make it safer. To design and test potential algorithms, we would like to make use of all the information from the data collected by a real driving platform. Such data has four major properties: it is large-scale, diverse, captured on the street, and with temporal information. Data diversity is especially important to test the robustness of perception algorithms. However, current open datasets can only cover a subset of the properties described above. Therefore, with the help of Nexar, we are releasing the BDD100K database, which is the largest and most diverse open driving video dataset so far for computer vision research. This project is organized and sponsored by Berkeley DeepDrive Industry Consortium, which investigates state-of-the-art technologies in computer vision and machine learning for automotive applications.
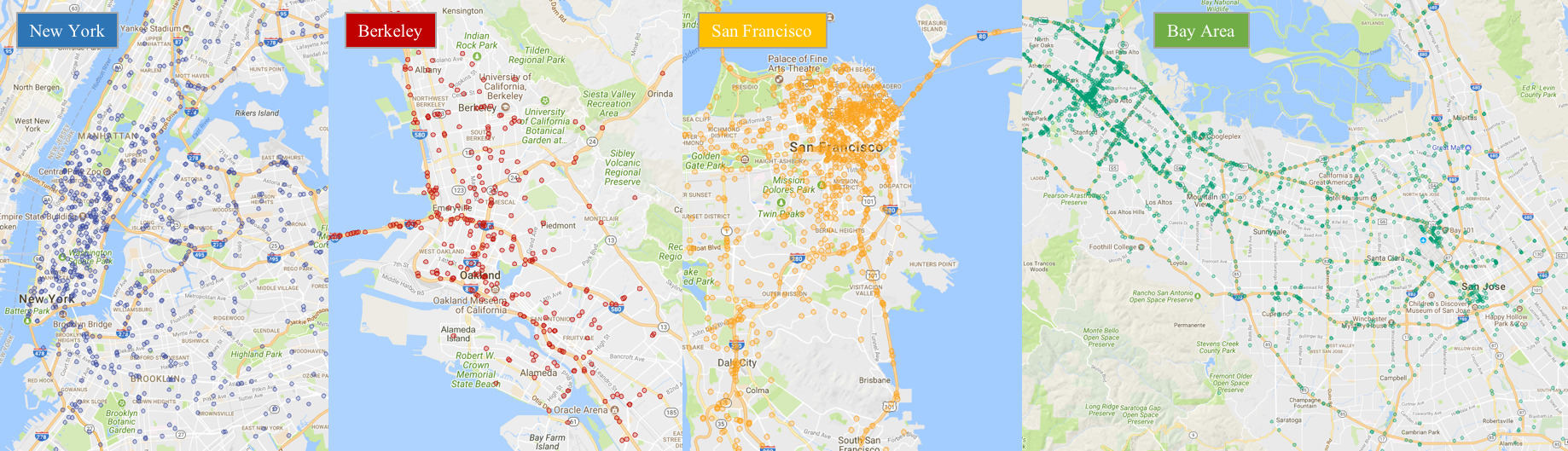
Locations of a random video subset.
As suggested in the name, our dataset consists of 100,000 videos. Each video is about 40 seconds long, 720p, and 30 fps. The videos also come with GPS/IMU information recorded by cell-phones to show rough driving trajectories. Our videos were collected from diverse locations in the United States, as shown in the figure above. Our database covers different weather conditions, including sunny, overcast, and rainy, as well as different times of day including daytime and nighttime. The table below summarizes comparisons with previous datasets, which shows our dataset is much larger and more diverse.
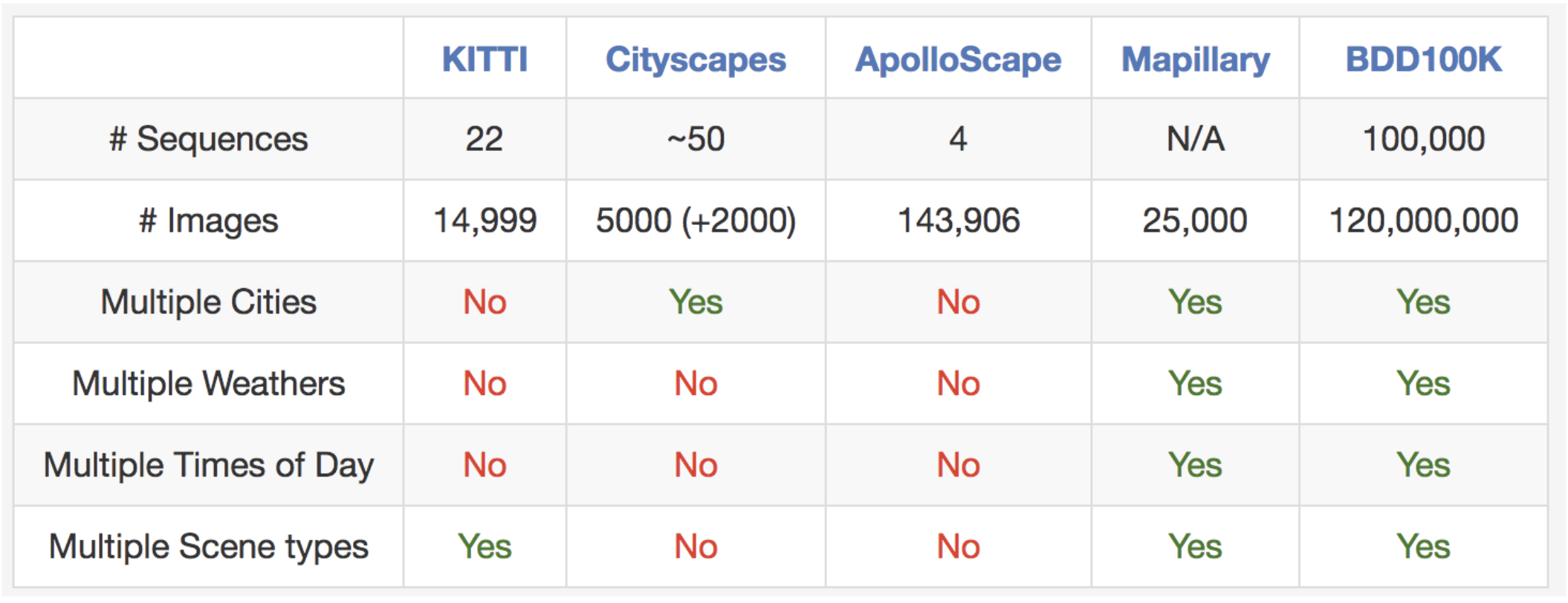
Comparisons with some other street scene datasets. It is hard to fairly compare
# images between datasets, but we list them here as a rough reference.
# Sequences are lists as a reference for diversity, but different datasets have different sequence lengths.
The videos and their trajectories can be useful for imitation learning of driving policies, as in our CVPR 2017 paper. To facilitate computer vision research on our large-scale dataset, we also provide basic annotations on the video keyframes, as detailed in the next section. You can download the data and annotations now at http://bdd-data.berkeley.edu.
Annotations
We sample a keyframe at the 10th second from each video and provide annotations for those keyframes. They are labeled at several levels: image tagging, road object bounding boxes, drivable areas, lane markings, and full-frame instance segmentation. These annotations will help us understand the diversity of the data and object statistics in different types of scenes. We will discuss the labeling process in a different blog post. More information about the annotations can be found in our arXiv report.

Overview of our annotations.
Road Object Detection
We label object bounding boxes for objects that commonly appear on the road on all of the 100,000 keyframes to understand the distribution of the objects and their locations. The bar chart below shows the object counts. There are also other ways to play with the statistics in our annotations. For example, we can compare the object counts under different weather conditions or in different types of scenes. This chart also shows the diverse set of objects that appear in our dataset, and the scale of our dataset – more than 1 million cars. The reader should be reminded here that those are distinct objects with distinct appearances and contexts.
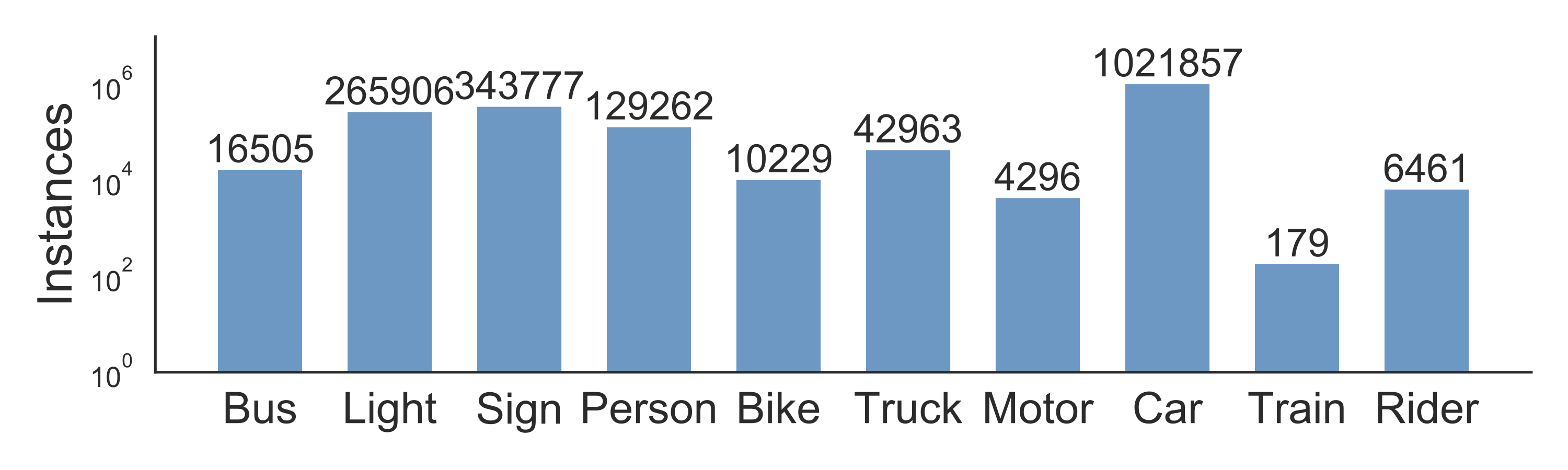
Statistics of different types of objects.
Our dataset is also suitable for studying some particular domains. For example, if you are interested in detecting and avoiding pedestrians on the streets, you also have a reason to study our dataset since it contains more pedestrian instances than previous specialized datasets as shown in the table below.
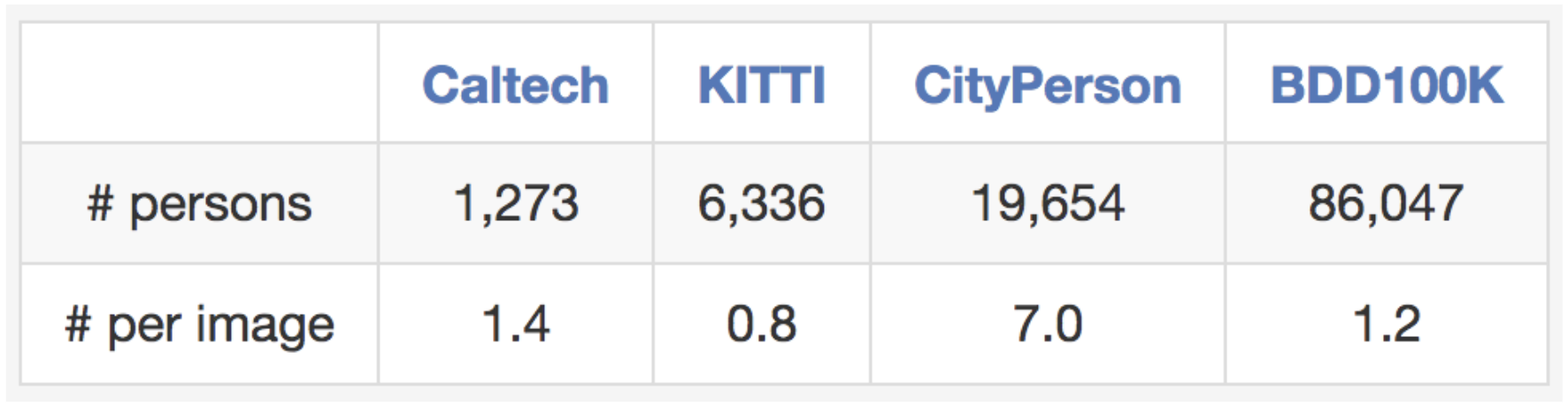
Comparisons with other pedestrian datasets regarding training set size.
Lane Markings
Lane markings are important road instructions for human drivers. They are also critical cues of driving direction and localization for the autonomous driving systems when GPS or maps does not have accurate global coverage. We divide the lane markings into two types based on how they instruct the vehicles in the lanes. Vertical lane markings (marked in red in the figures below) indicate markings that are along the driving direction of their lanes. Parallel lane markings (marked in blue in the figures below) indicate those that are for the vehicles in the lanes to stop. We also provide attributes for the markings such as solid vs. dashed and double vs. single.

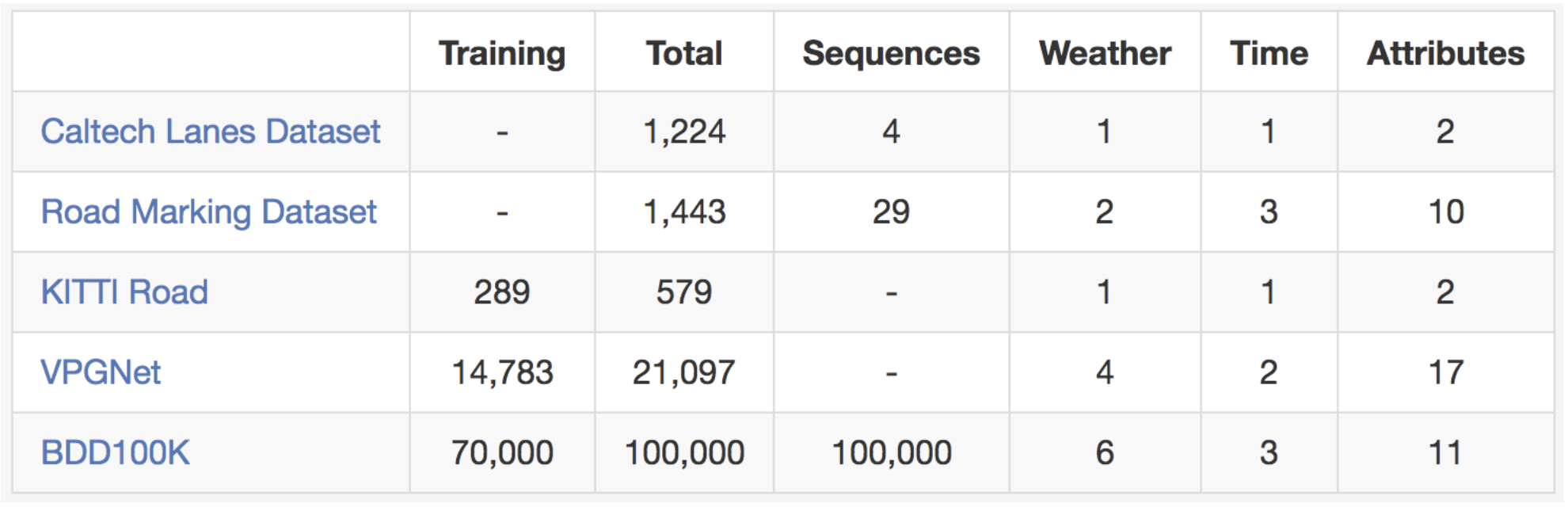
If you are ready to try out your lane marking prediction algorithms, please look no further. Here is the comparison with existing lane marking datasets.
Drivable Areas
Whether we can drive on a road does not only depend on lane markings and traffic devices. It also depends on the complicated interactions with other objects sharing the road. In the end, it is important to understand which area can be driven on. To investigate this problem, we also provide segmentation annotations of drivable areas as shown below. We divide the drivable areas into two categories based on the trajectories of the ego vehicle: direct drivable, and alternative drivable. Direct drivable, marked in red, means the ego vehicle has the road priority and can keep driving in that area. Alternative drivable, marked in blue, means the ego vehicle can drive in the area, but has to be cautious since the road priority potentially belongs to other vehicles.

Full-frame Segmentation
It has been shown on Cityscapes dataset that full-frame fine instance segmentation can greatly bolster research in dense prediction and object detection, which are pillars of a wide range of computer vision applications. As our videos are in a different domain, we provide instance segmentation annotations as well to compare the domain shift relative by different datasets. It can be expensive and laborious to obtain full pixel-level segmentation. Fortunately, with our own labeling tool, the labeling cost could be reduced by 50%. In the end, we label a subset of 10K images with full-frame instance segmentation. Our label set is compatible with the training annotations in Cityscapes to make it easier to study domain shift between the datasets.

Driving Challenges
We are hosting three challenges in CVPR 2018 Workshop on Autonomous Driving based on our data: road object detection, drivable area prediction, and domain adaptation of semantic segmentation. The detection task requires your algorithm to find all of the target objects in our testing images and drivable area prediction requires segmenting the areas a car can drive in. In domain adaptation, the testing data is collected in China. Systems are thus challenged to get models learned in the US to work in the crowded streets in Beijing, China. You can submit your results now after logging in our online submission portal. Make sure to check out our toolkit to jump start your participation.
Join our CVPR workshop challenges to claim your cash prizes!!!
Future Work
The perception system for self-driving is by no means only about monocular videos. It may also include panorama and stereo videos as well as other types of sensors like LiDAR and radar. We hope to provide and study those multi-modality sensor data as well in the near future.
Reference Links
Caltech, KITTI, CityPerson, Cityscapes, ApolloScape, Mapillary, Caltech Lanes Dataset, Road Marking Dataset, KITTI Road, VPGNet