Aldo Pacchiano, Jack Parker-Holder, Luke Metz, and Jakob Foerster
Nov 13, 2020
Goodhart’s Law is an adage which states the following:
“When a measure becomes a target, it ceases to be a good measure.”
This is particularly pertinent in machine learning, where the source of many of
our greatest achievements comes from optimizing a target in the form of a loss
function. The most prominent way to do so is with stochastic gradient descent
(SGD), which applies a simple rule, follow the gradient:
\[\theta_{t+1} = \theta_t - \alpha \nabla_\theta \mathcal{L}(\theta_t)\]
For some step size $\alpha$. Updates of this form have led to a series of
breakthroughs from computer vision to reinforcement learning, and it is easy to
see why it is so popular: 1) it is relatively cheap to compute using backprop
2) it is guaranteed to locally reduce the loss at every step and finally 3) it
has an amazing track record empirically.
Continue
Imagine that you are building the next generation machine learning model for handwriting transcription. Based on previous iterations of your product, you have identified a key challenge for this rollout: after deployment, new end users often have different and unseen handwriting styles, leading to distribution shift. One solution for this challenge is to learn an adaptive model that can specialize and adjust to each user’s handwriting style over time. This solution seems promising, but it must be balanced against concerns about ease of use: requiring users to provide feedback to the model may be cumbersome and hinder adoption. Is it possible instead to learn a model that can adapt to new users without labels?
Continue
The two most common perspectives on Reinforcement learning (RL) are optimization and dynamic programming. Methods that compute the gradients of the non-differentiable expected reward objective, such as the REINFORCE trick are commonly grouped into the optimization perspective, whereas methods that employ TD-learning or Q-learning are dynamic programming methods. While these methods have shown considerable success in recent years, these methods are still quite challenging to apply to new problems. In contrast deep supervised learning has been extremely successful and we may hence ask: Can we use supervised learning to perform RL?
In this blog post we discuss a mental model for RL, based on the idea that RL can be viewed as doing supervised learning on the “good data”. What makes RL challenging is that, unless you’re doing imitation learning, actually acquiring that “good data” is quite challenging. Therefore, RL might be viewed as a joint optimization problem over both the policy and the data. Seen from this supervised learning perspective, many RL algorithms can be viewed as alternating between finding good data and doing supervised learning on that data. It turns out that finding “good data” is much easier in the multi-task setting, or settings that can be converted to a different problem for which obtaining “good data” is easy. In fact, we will discuss how techniques such as hindsight relabeling and inverse RL can be viewed as optimizing data.
Continue
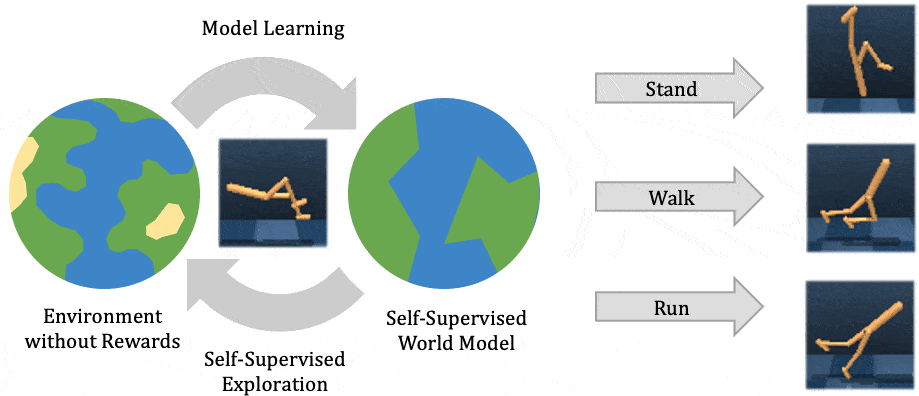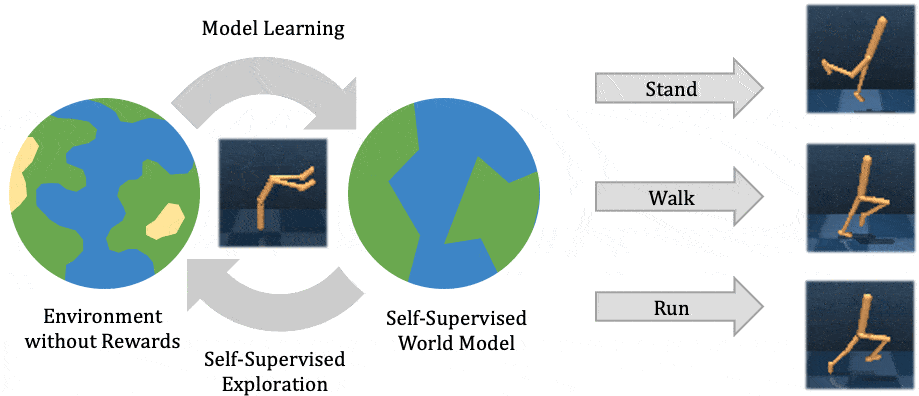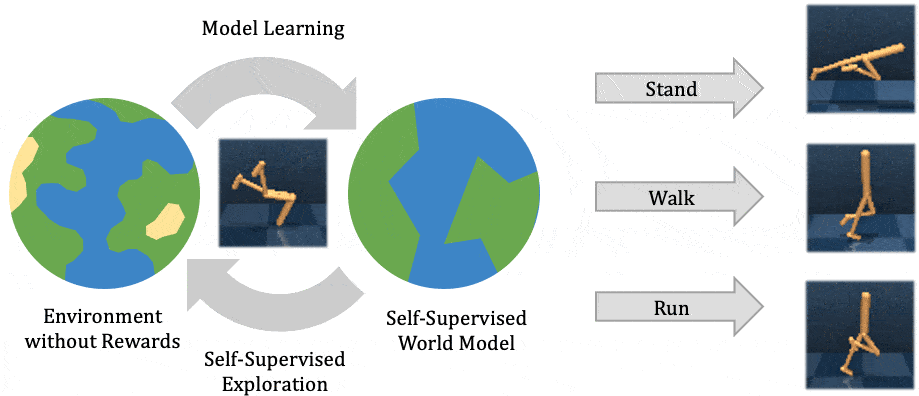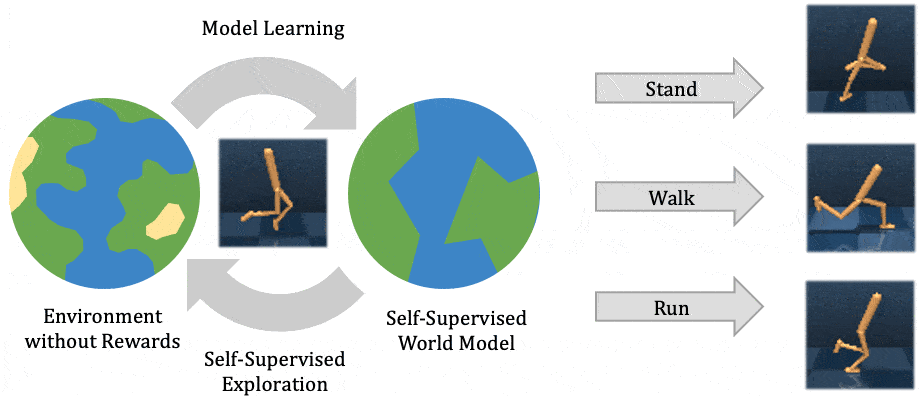
This post is cross-listed on the CMU ML blog.
To operate successfully in unstructured open-world environments, autonomous intelligent agents need to solve many different tasks and learn new tasks quickly. Reinforcement learning has enabled artificial agents to solve complex tasks both in simulation and real-world. However, it requires collecting large amounts of experience in the environment, and the agent learns only that particular task, much like a student memorizing a lecture without understanding. Self-supervised reinforcement learning has emerged as an alternative, where the agent only follows an intrinsic objective that is independent of any individual task, analogously to unsupervised representation learning. After experimenting with the environment without supervision, the agent builds an understanding of the environment, which enables it to adapt to specific downstream tasks more efficiently.
In this post, we explain our recent publication that develops Plan2Explore. While many recent papers on self-supervised reinforcement learning have focused on model-free agents that can only capture knowledge by remembering behaviors practiced during self-supervision, our agent learns an internal world model that lets it extrapolate beyond memorized facts by predicting what will happen as a consequence of different potential actions. The world model captures general knowledge, allowing Plan2Explore to quickly solve new tasks through planning in its own imagination. In contrast to the model-free prior work, the world model further enables the agent to explore what it expects to be novel, rather than repeating what it found novel in the past. Plan2Explore obtains state-of-the-art zero-shot and few-shot performance on continuous control benchmarks with high-dimensional input images. To make it easy to experiment with our agent, we are open-sourcing the complete source code.
Continue




Our method learns complex behaviors by training offline from prior datasets
(expert demonstrations, data from previous experiments, or random exploration
data) and then fine-tuning quickly with online interaction.
Robots trained with reinforcement learning (RL) have the potential to be used
across a huge variety of challenging real world problems. To apply RL to a new
problem, you typically set up the environment, define a reward function, and
train the robot to solve the task by allowing it to explore the new environment
from scratch. While this may eventually work, these “online” RL methods are
data hungry and repeating this data inefficient process for every new problem
makes it difficult to apply online RL to real world robotics problems. What if
instead of repeating the data collection and learning process from scratch
every time, we were able to reuse data across multiple problems or experiments?
By doing so, we could greatly reduce the burden of data collection with every
new problem that is encountered. With hundreds to thousands of robot
experiments being constantly run, it is of crucial importance to devise an RL
paradigm that can effectively use the large amount of already available data
while still continuing to improve behavior on new tasks.
The first step towards moving RL towards a data driven paradigm is to consider
the general idea of offline (batch) RL. Offline RL considers the problem of
learning optimal policies from arbitrary off-policy data, without any further
exploration. This is able to eliminate the data collection problem in RL, and
incorporate data from arbitrary sources including other robots or
teleoperation. However, depending on the quality of available data and the
problem being tackled, we will often need to augment offline training with
targeted online improvement. This problem setting actually has unique
challenges of its own. In this blog post, we discuss how we can move RL from
training from scratch with every new problem to a paradigm which is able to
reuse prior data effectively, with some offline training followed by online
finetuning.
Continue
Sophia Stiles
Aug 16, 2020
Editor’s Note: The following blog is a special guest post by a recent graduate
of Berkeley BAIR’s AI4ALL summer program for high school students.
AI4ALL is a nonprofit dedicated to increasing diversity and inclusion in AI
education, research, development, and policy.
The idea for AI4ALL began in early 2015 with Prof. Olga Russakovsky, then
a Stanford University Ph.D. student, AI researcher Prof. Fei-Fei Li, and Rick
Sommer – Executive Director of Stanford Pre-Collegiate Studies. They founded
SAILORS as a summer outreach program for high school girls to learn about
human-centered AI, which later became AI4ALL. In 2016, Prof. Anca Dragan
started the Berkeley/BAIR AI4ALL camp, geared towards high school students from
underserved communities.
Continue
The case fatality rate quantifies how dangerous COVID-19 is, and how risk of death varies with strata
like geography, age, and race. Current estimates of the COVID-19 case fatality rate (CFR) are biased
for dozens of reasons, from under-testing of asymptomatic cases to government misreporting. We provide
a careful and comprehensive overview of these biases and show how statistical thinking and modeling can
combat such problems. Most importantly, data quality is key to unbiased CFR estimation. We show that a
relatively small dataset collected via careful contact tracing would enable simple and potentially more
accurate CFR estimation.
Continue
Despite recent advances in artificial intelligence (AI) research, human
children are still by far the best learners we know of, learning impressive
skills like language and high-level reasoning from very little data. Children’s
learning is supported by highly efficient, hypothesis-driven exploration: in
fact, they explore so well that many machine learning researchers have been
inspired to put videos like the one below in their talks to motivate research
into exploration methods. However, because applying results from studies in
developmental psychology can be difficult, this video is often the extent to
which such research actually connects with human cognition.

A time-lapse of a baby playing with toys. Source.
Continue